
.svg)

TL;DR
- Long context didn’t kill retrieval. Bigger windows add cost and noise; retrieval focuses attention where it matters. Additionally, RAG is 8-82× cheaper than long context approaches for typical workloads, with better latency.
- Multimodal is Essential: grep and lexical search work amazingly well for code, but it’s blind to diagrams and figures. Enterprise content needs semantic + vision-aware retrieval and reranking.
- Conditional Over Automatic: RAG in 2025 is modular and should decide if, what, where, and how to retrieve, not retrieve blindly. This means that metadata matters: invest in offline precomputation to describe collections. Runtime decisions depend on knowing what you have.
- Evaluate Granularly: Stage-wise metrics are mandatory. End-to-end evaluation alone guarantees you'll struggle to improve.
The age of agents didn't make retrieval obsolete, it made intelligent retrieval essential.
This post is based on Amélie Chatelain's presentation at Weights & Biases Fully Connected 2025.
Since late 2023, the machine learning community has been repeatedly proclaiming the death of Retrieval-Augmented Generation (RAG). With each new announcement of larger context windows for Large Language Models (LLMs) - Claude's 100K, Gemini's 1M, and beyond - the narrative strengthened: "Why retrieve when you can just dump everything into context?"
Yet here we are in 2025, and retrieval is more alive than ever. Not as the naive pipeline of 2023, but as a sophisticated, conditional attention policy within agentic systems. This post explores why RAG didn't die, it matured, and why we strongly believe at LightOn that a strong retrieval pipeline is essential.
The RAG Hype Cycle: A Timeline

Picture May 2020. While the world was grappling with lockdowns, Facebook's AI Research team published a paper that would define the next half-decade of enterprise AI: RAG, a method to give language models access to external knowledge without retraining. Then came November 2022 and the drop of ChatGPT. Suddenly everyone cared about large language models and GenAI, the floodgates opened.
By early 2023, RAG reached its peak of inflated expectations. Venture capital flowed freely. Startups sprouted overnight, each promising that RAG would solve hallucinations, democratize enterprise knowledge, and revolutionize how we work. Vector databases became the new must-have infrastructure. The narrative was simple and seductive: RAG for everyone, solves everything.
But storm clouds gathered quickly. In May 2023, Anthropic released Claude with 100K tokens of context. The first cracks appeared in RAG's armour. Whispers started: "If models can hold entire codebases in memory, why retrieve at all?"
February 2024 brought the deluge. Google's Gemini arrived with 1 million tokens of context. That's roughly the entire Lord of the Rings trilogy. Tech Twitter erupted with hot takes. Blog posts proliferated: "RAG is Dead: Why Retrieval-Augmented Generation Is No Longer the Future of AI." The logic seemed bulletproof: why build complex retrieval pipelines when you could just... dump everything in context?
The proclamations of death continued. November 2024: Anthropic released the Model Context Protocol (MCP). "MCP has killed RAG!" declared the headlines, conveniently ignoring that MCP is literally a retrieval mechanism. The R in RAG was crying.
February 2025 delivered what many saw as the final nail in the coffin. Claude Code launched using grep and file globbing for code navigation, no vector search required. This was in contrast to other agentic code tools, such as Cursor, which index code for retrieval. Industry consensus seemed to converge: RAG was a 2023 fad, a temporary workaround now obsolete.
Except... none of these "RAG killers" actually killed retrieval. They just made it evolve. Let’s discuss it!
The Core Question: Did Long Context Really Kill RAG?
To answer this, we need to examine what "just dump everything in the context window" actually costs: both economically and in terms of performance.
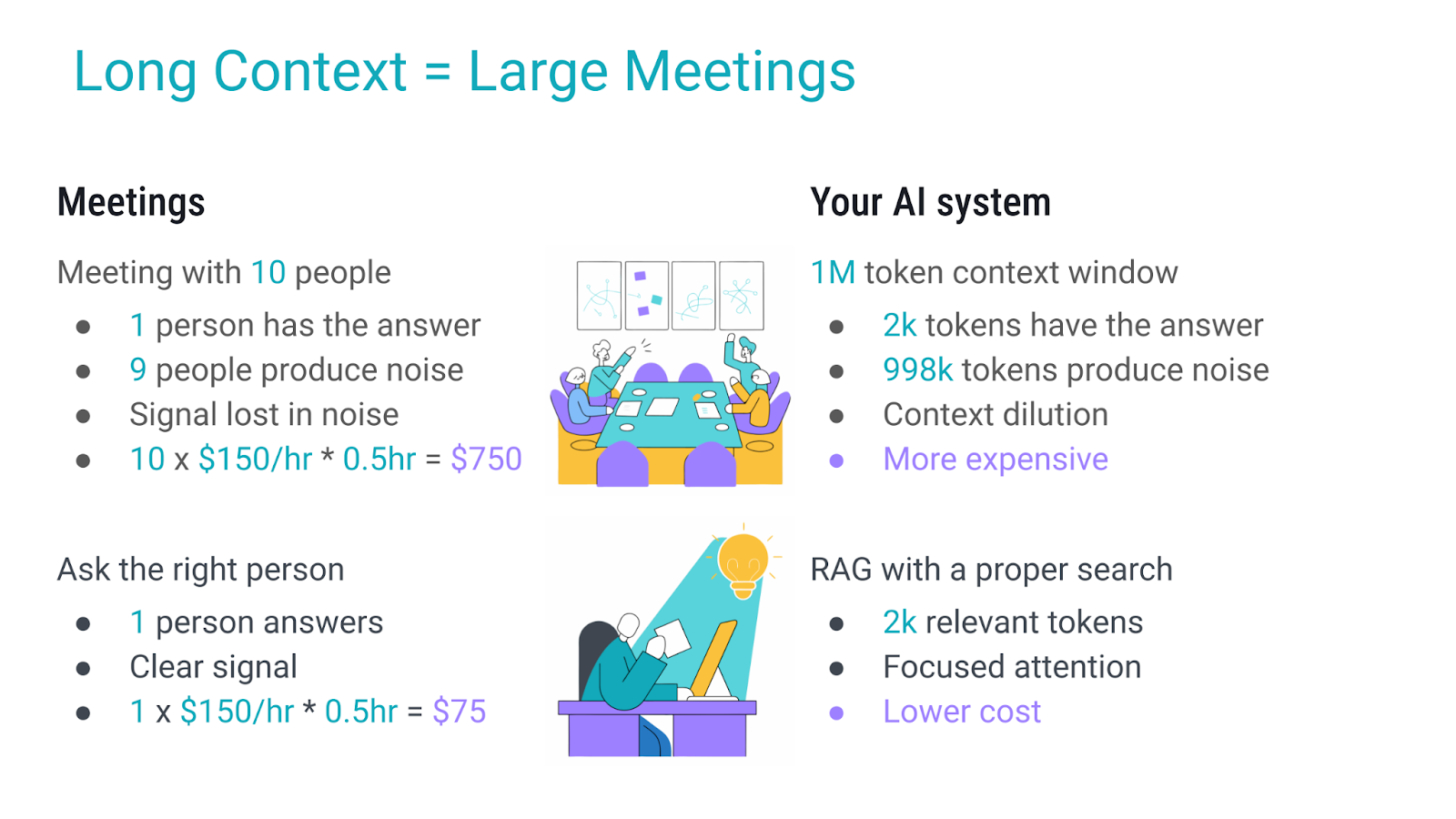
The Meeting Analogy: Long Context as Inefficient Communication
Consider this familiar scenario: someone has a simple question, but instead of finding the right person to ask, they schedule a meeting with 10 people. The result?
Ten attendees cost $750 for thirty minutes; asking the single expert would have cost $75. Long contexts behave the same: invite a million tokens when only a few thousand carry the answer, and you drown the signal in noise and pay for it. A focused RAG pipeline is asking the expert first.
The Real Economics of Long Context
When I prepared the talk, I looked for hard numbers comparing “dump everything in context” vs. “retrieve minimally.” I couldn’t find them, so I built a long‑context calculator. You may find it deployed on streamlit here, and the code is available on github, so you can adjust the heuristic to match your own business case.
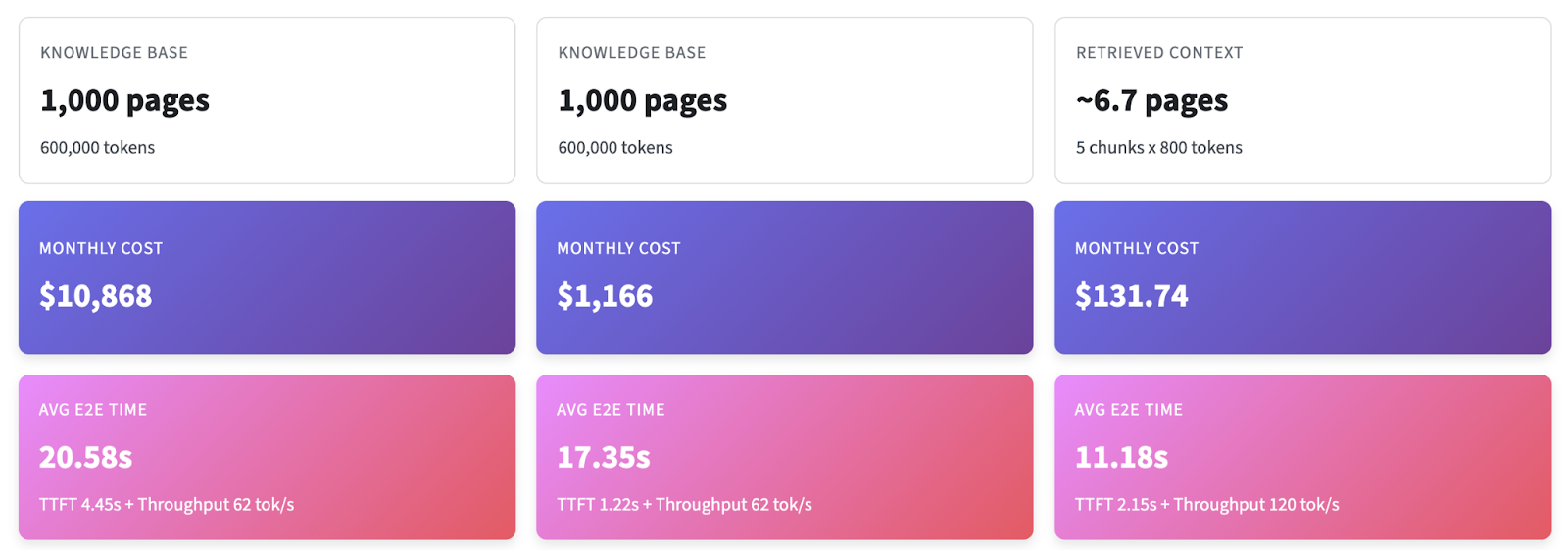
The punchline: even with caching, long‑context workflows add complexity and still lag on latency/price; retrieving ~5 targeted chunks remains an order of magnitude cheaper under realistic assumptions because generation dominates end‑to‑end time.
The Long Context Illusion: Capacity ≠ Comprehension
The notion that 1M tokens solves all problems reflects a fundamental misunderstanding.
First, consider what 1M tokens actually represents: a million tokens sounds vast until you realize that common codebases (text only) can blow past it.

Multimodal content makes thing much worse: a single figure can cost ~1k–1.5k tokens. Your budget evaporates quickly. For intuition I used a nerdy yardstick: The Lord of the Rings (courtesy of Antoine Chaffin). The Fellowship book is ~250k tokens; the trilogy + appendices ~700k; the movie, non-extended version (2h58m @ 24 fps) would be ~171M “image tokens” if you naïvely tokenized frames. One million tokens isn’t the infinite canvas it feels like on paper.

Moreover, research consistently shows that model performance degrades as context length increases. Benchmarks repeatedly show that performance depends on model, modality, and even where the answer sits—the classic “lost in the middle.”
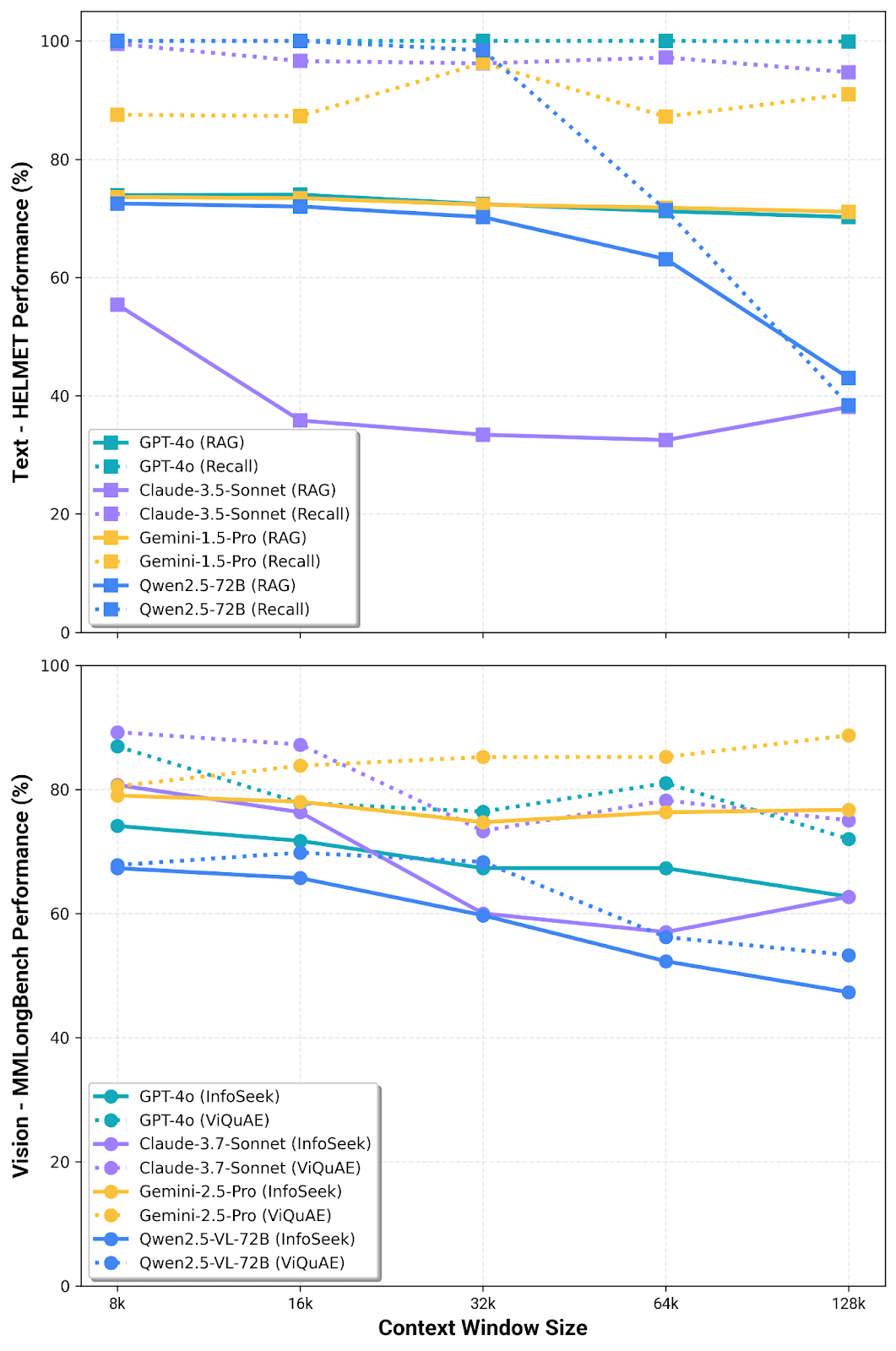
This isn't a temporary engineering problem: it's attention dilution at scale. More context doesn't mean better understanding; it means more noise to filter.
Why grep Isn't Enough: The Multimodal Challenge
Claude Code's success with grep-based (lexical) retrieval sparked questions about whether semantic search is necessary. The answer depends entirely on your content.
When grep Works
Grep excels when your documents are:
- Plain text with consistent terminology
- Well-structured code with meaningful identifiers
- Content where exact string matching is sufficient
Claude Code operates in this domain: searching codebases where function names, variable names, and comments are designed for human readability and grep-ability.
Think of grep as DM’ing colleagues: you ping, you wait, you expand the search if needed. It doesn’t require indexing, it is easy to set up - though, it can end up being slower and more expensive than using a vector database for searches (see my calculator again).
It works - until the answer is a diagram.
When grep Fails: The Visual Reality
But enterprise knowledge doesn't look like code. Consider this query:
Query: "Which elements are above the casing hanger?"
Your document: A technical diagram from an oil & gas operation manual showing well construction with visual labels and spatial relationships.

grep cannot:
- Parse spatial relationships in images
- Understand visual hierarchies in diagrams
- Extract information from charts, graphs, or schematic drawings
- Handle the semantic meaning of "above" in a visual context
You can't grep a diagram. This is where multimodal RAG becomes essential: combining vision-language models for retrieval with semantic understanding of both text and visual content.
Production systems need:
- Multimodal embedding models that handle text + images
- Vision-capable rerankers, such as MonoQwen, that understand visual context and ensure that the context provided to your LLM is spot on
Intelligent Retrieval: RAG in the Age of Agents
The biggest shift from 2023 to 2025 is that RAG isn’t “always retrieve k chunks.” It’s a decision stack: conscious choices that allocate attention.
The Four Decision Points
Modern retrieval systems make conditional decisions at every stage:
1. IF: Tool Routing (Do we need a meeting?)
Not every query requires retrieval. Agents should make decisions based on:
- The query type: is it a factual query, a summarisation query, …?
- Recency requirements: is the current knowledge sufficient?
- Security/privacy: should I look this up online?
Examples:
- "What's 2+2?" → Direct answer, no retrieval
- "What are our Q3 revenue numbers?" → Needs retrieval in the company knowledge base
- "What will be the weather in Paris this weekend?” → Recent query, should look online
📊 Evaluate this routing decision using F1 against an oracle router; track latency & cost to avoid over‑tooling simple asks.
2. WHAT: Tool Argument Writing (What is our agenda?)
If retrieval is needed, construct the optimal query relying on user context (their role, department, access permissions, historical data, etc) and domain understanding (building filters via entity recognition, query expansion, etc).
Example transformation:
{
"query": "What are the main numbers of LightOn's Q3 report?",
"filters": {
"time_range": {
"start": "2025-07-01",
"end": "2025-09-30"
},
"document_type": "report",
"department": "finance"
}
}📊 Evaluate the way your system understands queries with things like retrieval recall/precision deltas with vs. without rewrites; filter extraction accuracy.
3. WHERE & HOW: Retrieval Strategy (Who do we invite to our meeting? Who speaks first?)
Pick a retrieval strategy: lexical for code, semantic/hybrid for prose, multimodal if figures carry the answer; pick the right collection using rich metadata and offline precompute so you don’t stall the user at query time.
Example scenario:
- Financial report query → Use financial docs collection, and vision-based to make sure you capture the various diagrams in your report.
- Mention of specific code function → Use codebase collection
- Ambiguous query → Search multiple collections, rerank combined results
✨ The critical insight here is you cannot know which collection to search, what strategy to use without rich metadata about collection contents. This requires offline precomputation - investing resources upfront to characterize your collections so runtime decisions are fast and accurate.
📊 Evaluate both your retrieval and reranking abilities by measuring pre‑ vs. post‑rerank retrieval metrics separately.
4. GENERATE: Answer with Right Context (Writing accurate and useful meeting minutes)
After retrieval and reranking, generate from the smallest faithful context.
📊 Evaluate the quality of your answer on groundedness to sources, exactness on tasks.
Critical: This should be your last evaluation measure, not your only one. Why, you ask?
Evaluation: Isolating Failures in Complex Systems
The shift to conditional, multi-stage retrieval creates a critical challenge: when agents fail, where did they break?
Failures cascade. If tool routing is wrong, everything downstream fails. If query construction is poor, retrieval gets irrelevant docs. Evaluations must isolate each stage.
Only with this granular visibility can you:
- Identify which component to improve
- Understand whether failures are systematic or edge cases
- Optimize cost vs. quality tradeoffs at each stage
- Make data-driven decisions about model selection, prompting strategies, and system architecture
Attempting to bypass the granular evaluation process and only measuring the quality of the final answer is a recipe for disaster. You will end up with a non-functional pipeline and no idea why.
Conclusion: RAG Didn't Die, It Grew

The past two years didn’t kill retrieval: they forced RAG to mature. Today, RAG is intentional attention: decide if to retrieve; if yes, decide what, where, and how; keep the context lean; measure everything. In other words, stop scheduling giant meetings “just in case.” Ask the right expert, bring only what you need, and keep the conversation sharp. That’s RAG in the age of agents.
This evolution parallels the broader shift from pipelines to agents. The key insights:
- Deciding IF to Retrieve: Knowing when to skip the meeting: not every query needs external context.
- Routing Intelligently: Asking the expert, not the department: targeted retrieval relying on metadata beats exhaustive search.
- Measuring Everything: Tracking every decision point: granular evaluation is non-negotiable for complex systems.
The future isn't "RAG vs. long context": it's intelligent systems that use both strategically, deciding in real-time which approach serves each query best.
RAG is dead. Long live RAG.
Curious how LightOn builds retrieval that thinks before it fetches?
Explore our latest research and products on intelligent retrieval or get in touch to see it in action 👉 contact us!



.avif)
.avif)
