
.svg)

TL;DR
LightOnOCR-1B sets a new standard for how AI reads and understands business information and it does so at unprecedented speed. For decades, OCR has been about recognizing text; understanding it has always been out of reach. With LightOnOCR-1B, LightOn transforms document parsing from a slow, mechanical process into a fast, end-to-end semantic engine: machines don’t just “see” text, they comprehend it, in real time. This leap makes every contract, report, and archived document instantly usable by modern AI systems.
At enterprise scale, speed is not a luxury, it’s a necessity. LightOnOCR-1B processes and structures massive document collections in record time, enabling organizations to index and unlock years of unstructured data effortlessly. Integrated into LightOn’s Private Enterprise Search, it turns organizational history into a living, searchable source of intelligence. In short: we make sense of your past, empowering GenAI to reason, summarize, and act upon your company’s entire knowledge base.
What OCR was to the digital age, LightOnOCR-1B is to the intelligence age, the missing bridge between business documents and machine understanding, now faster than ever.
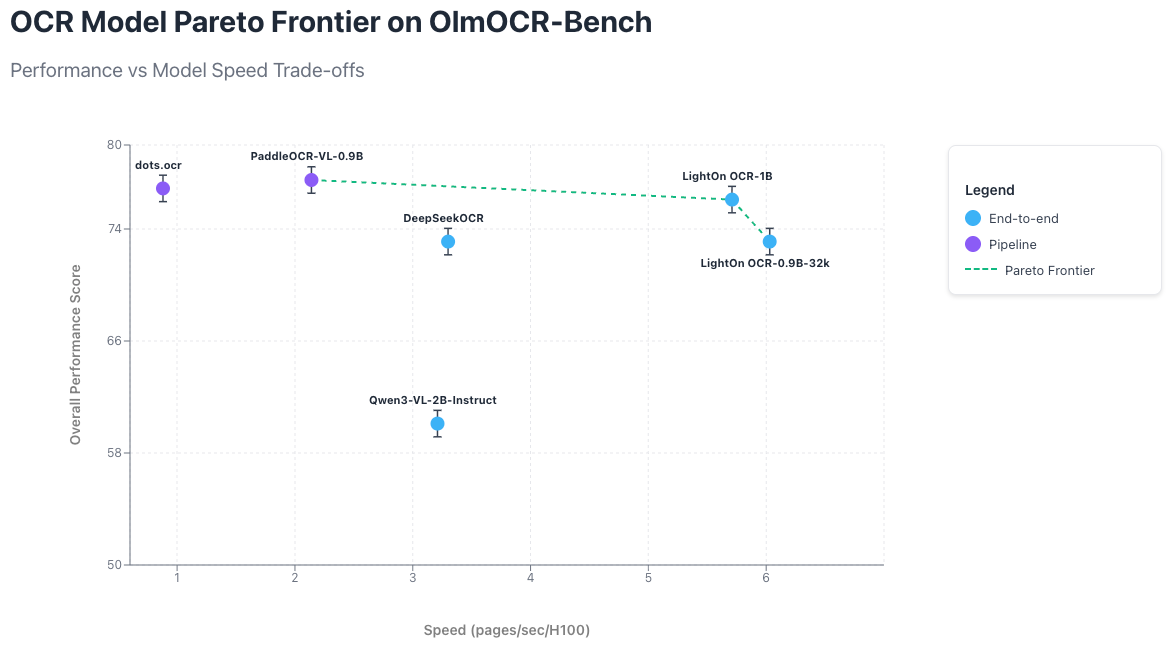
This blogpost introduces LightOnOCR-1B, a vision–language model for OCR that achieves state-of-the-art performance in its weight class while outperforming much larger general-purpose models. It achieves these results while running 6.49× faster than dots.ocr, 2.67× faster than PaddleOCR-VL-0.9B and 1.73× faster than DeepSeekOCR. Finally, unlike most recent approaches that rely on complex, non-trainable pipelines, LightOnOCR-1B is fully end-to-end trainable and easily fine-tunable for specific languages or domains. One of the key ingredients of LightOnOCR is its diverse large-scale PDF training corpus which will also be released with an open license soon.
Introduction
OCR has become essential for modern multimodal understanding of documents and is critical for many applications ranging from information extraction to RAG solutions. Parsing documents is inherently challenging because it involves understanding high-resolution, text-dense and structurally complex images.
In this context, we release LightOnOCR, a compact, end-to-end model that delivers state-of-the-art document understanding with lightning speed and low cost. Competing systems(including newest releases) often rely on multiple moving parts to boost performance, but this added complexity makes them brittle, difficult to train, and prone to break when adapting to new data or domains. LightOnOCR, on the other hand, is a single unified model — fully differentiable and easy to optimize end-to-end — capable of handling complex layouts such as tables, forms, receipts, and scientific notation without fragile multi-stage pipelines.
LightOnOCR is built by training a strong vision transformer with a lean language backbone and distilled from high-quality open VLMs. It is also highly efficient — processing 5.71 pages per second on a single H100 GPU, or roughly 493,000 pages per day. At current cloud pricing, that translates to less than $0.01 per 1,000 pages, making it several times cheaper than running larger OCR VLMs. We believe this will be of great interest to the community: the model is simple, stable, and inexpensive to fine-tune, making it easy to adapt to new domains, layouts, or languages.
LightOnOCR is also available in two other variants with a pruned vocabulary of 32k tokens and 16k tokens, offering additional speedup for European languages while maintaining almost the same accuracy.
The work highlights the strong potential for small end-to-end models distilled from larger models, and establishes a new Pareto frontier for OCR models.
You can find the model weights here and easily deploy with vLLM with the following command:
# get the latest vllm nightly until v0.11.1 is released
uv pip install -U vllm \\
--torch-backend=auto \\
--extra-index-url <https://wheels.vllm.ai/nightly> \\
--prerelease=allow
# deploy the server and enjoy!
vllm serve lightonai/LightOnOCR-1B-1025 \\
--limit-mm-per-prompt '{"image": 1}' \\
--async-schedulingResults
We present our main results on Olmo-Bench the most common OCR benchmark, along with a comparison of inference speed against competing OCR systems.We choose not to include OmniDocBench for two different reasons: first the model is not optimized for Chinese and second, our model is optimized to output full page Markdown and not HTML. We discuss this a bit more in this section.
Quality
LightOnOCR delivers performance on par with the latest state-of-the-art OCR systems. The model reaches state-of-the-art performance on Olmo-Bench for its size, including their most recent releases, and outperforms or closely matches much larger general-purpose VLMs without any training on OlmoOCR-mix. Indeed, unlike several reported baselines, LightOnOCR achieves these results without any benchmark-specific fine-tuning. Being a fully end-to-end model rather than a pipeline, it can be easily fine-tuned on specific domains such as OlmoOCR-mix to further improve performance, as shown in a later section.
LightOnOCR notably beats DeepSeek OCR and performs on par with dots.ocr, despite the latter being roughly three times larger, and remains within the error margin of the pipeline-based PaddleOCR-VL and surpasses the larger Qwen3-VL-2B by 16 overall points. Beyond quality, its key advantage lies in efficiency: it matches the best available models while running significantly faster.

Speed
To evaluate the speed–performance trade-offs of different OCR models, we use the Olmo-Bench dataset, which contains 1,402 PDF documents. For a fair comparison, we select models that are both among the best-performing and of a similar size to ours. For models with publicly reported scores, we retain their published results. Each model is benchmarked using its official library or provided scripts, with all experiments run on a single H100 GPU (80 GB). In every case, we aim to fully utilize GPU memory, and all models are served through the vLLM inference engine for consistency. For DeepSeekOCR we use the recommended model variant and for Qwen3-VL-2B-Instruct we use the qwenvl markdown format recommended in the cookbook in order to transcribe documents.
If a model cannot sustain the full workload, for example due to vLLM server crashes, we gradually reduce the number of workers until it runs stably. The resulting Markdown outputs are then evaluated on Olmo-Bench to measure accuracy and overall performance.
Pipeline-based approaches such as dots.ocr or PaddleOCR-VL require multiple model calls per page and introduce additional cropping and preprocessing overheads. While such pipelines can improve quality through specialized heuristics, they do so at a significant cost in speed. In contrast, our end-to-end model performs a single call per page and employs no retry or correction logic, resulting in a simpler, faster, and more efficient inference process.
So that’s LightOnOCR, an accurate and fast OCR model. But how did we achieve this? In the following section, we dive into the technical details behind LightOnOCR-1B: its architecture, the dataset we built, and the training setup that made it possible.
Technical details
The following section presents the model architecture, dataset curation, experimental setup, evaluation and ablations.
Model Architecture
The model is a 1B VLM obtained by combining a native resolution Vision Transformer (ViT) initialized from Pixtral and the Qwen3 language model architecture through a multimodality projection layer randomly initialized. In this layer, the vision tokens are first downsampled by a factor of 4 before being fed to the language model to reduce computational requirements. We also remove both the image break and image end tokens to simplify the architecture and use fewer image tokens overall per image.

Training Dataset Curation
Although we start from pre-trained models, they are not aligned at first and so the training is of utmost importance. Our approach follows a knowledge distillation paradigm: we leverage a larger vision-language model to transcribe a large corpus of document pages, then train a smaller, specialized model on this synthetic dataset after careful curation.We employed Qwen2-VL-72B-Instruct as our base model, prompting it to transcribe content into Markdown with LaTeX notation. Markdown offers a lightweight, human-readable structure that is more token-efficient than HTML. It provides enough markup to preserve hierarchy and layout without unnecessary syntax, helping the model focus on content rather than formatting. Its simplicity also makes it easy to parse and convert into other formats, making it ideal for OCR output and downstream processing.Despite generally high-quality outputs, we observed several systematic issues requiring correction: generation loops, extraneous Markdown code block delimiters, superfluous formatting elements, and format inconsistencies (occasional HTML tables or LaTeX environments for arXiv-sourced documents). We therefore implemented a comprehensive normalization pipeline to ensure consistent, relevant transcriptions.
Normalization Procedures:
- Loop detection: We applied n-gram frequency analysis combined with prefix-based line clustering using Jaccard similarity metrics to identify and filter repetitive generation artifacts. We also discard samples that didn’t finish generation for a max output tokens of 6144, as these are likely repetitions or excessively long samples.
- Deduplication: We computed cryptographic hashes of sequences across our large-scale dataset to identify and remove duplicate samples.
- Image placeholder standardization: We normalized all image references to the format
, enabling future users to substitute these with descriptive alt-text. - Hallucination filtering: Since our dataset contained ground truth transcriptions from legacy OCR systems, we computed similarity scores between VLM outputs and reference OCR fields. This metric enabled the detection of hallucinations and generation failures, allowing us to filter samples with anomalously low similarity scores (e.g., outputs containing "I don't see anything on this image" or other null responses).
This gives a dataset of 17.6 million pages and 45.5 billion tokens, combining both vision and text tokens rendered at native resolution, with a maximum image size of 1540 pixels.
This dataset will be permissively released soon. Also note that we use only this dataset in all of our ablations and final training (i.e, the final model is not trained using the Olmo-mix training set).
Experimental Setup
After carefully designing both the architecture and the dataset, what was left was to train the model and evaluate its performance. All ablations and experiments use the same model and data to ensure consistent and comparable results.
Evaluation
Our evaluation process relies on two open source benchmarks: OmniDocBench and OlmOCR-Bench, adapted to our specific setup as follows:
- OlmOCR-Bench: 1,402 PDF documents and 7,010 test cases covering a wide range of document types, extraction challenges and languages. This benchmark relies on automatic unit tests instead of edit distance for clear, reproducible evaluation. We do not report the headers and footers metric, as it rewards excluding visible text like titles or page numbers; while our goal is full-page transcription. In fact, a model that outputs nothing at all would score 100%, making the metric misleading for our use case. Note that we demonstrate later that finetuning enables one to recover the feature if desired. See [Section]
- OmniDocBench v1.0 : consists of 981 PDF pages spanning 9 document types, 4 layout styles, and 3 language categories, divided into English and Chinese subsets. The benchmark relies heavily on edit distance as a metric, which is highly sensitive to formatting and syntax.
Please note that LightOnOCR output tables in Markdown format. We chose chose this representation because it is lightweight, easy to parse, and significantly more token-efficient than HTML, making it ideal for both training and downstream processing.. For compatibility with OmniDocBench’s HTML-based evaluation, we apply a simple regex-based post-processing step that detects Markdown tables and converts them into HTML. This conversion is intentionally minimal and systematic, and as such, can only underestimate our model’s true performance on table extraction. Note that we demonstrate later that changing the formatting of tables in our training dataset to HTML significantly improves the scores we obtain on the benchmark. This highlights its sensitivity to formatting conversion. See section.
Should you perform a 2-stage training?
One of the questions we wanted to answer was whether the popular two-stage training framework brings measurable benefits in our setup. This framework typically consists of first training the multimodal projection layer while freezing both the ViT and language model, then in a second stage unfreezing the entire model for full training. The idea is that during the initial alignment phase, only a small amount of data may be needed, while the second stage leverages the full dataset for training.
We freeze all parameters of the vision and language backbones and train only the multimodality projection for 768 000 samples using a high learning rate. We then proceed to full model training at a lower learning rate. The goal was to better preserve the features of the high-quality backbone models we used by allowing the multimodality projection to align first.
Table 1. Comparison of one-stage and two-stage training results on olmOCR-Bench.
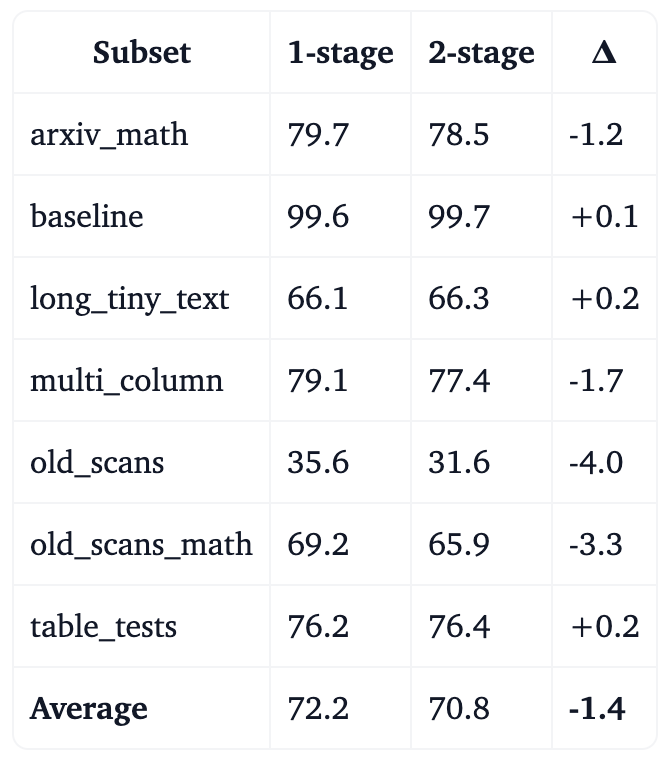
We can see that the difference in performance between the two-stage setup and standard single-stage training is minimal with single-stage outperforming two-stage overall. We therefore moved away from the two-stage approach for simplicity. We believe this outcome is largely due to the scale of our dataset, which is significantly larger than those used in most comparable studies. This dataset will be released in a next step under an open license to support further research and development in open-source OCR and document understanding.
This is similar to the findings in FineVision, where 2-stage training brings only marginal gains except for some tasks like OCRBench where the gains seemed to be important. Here, we confirm that multi-stage training does not provide any benefit even for OCR at 1B model size.
Is it worth to use a larger teacher model for data annotation?
We trained two models on an identical subset (11M samples) of our dataset, annotated either with Qwen2-VL-7B or Qwen2-VL-72B, to understand whether using a larger teacher model leads to better downstream performance. Both models share the same architecture and training setup; only the source of annotations differs.
The results below show a clear advantage for data annotated by the larger teacher.
Table 2. Comparison of datasets annotated with Qwen2-VL-7B vs Qwen2-VL-72B on olmOCR-Bench.

These results indicate that while both teacher models produce usable annotations, the larger 72B model yields consistently stronger performance across all categories. The improvement is especially visible on complex structured layouts such as multi-column pages, long tiny text, tables, and mathematical content.
This suggests that, for OCR, annotation quality scales with teacher size, and investing in a larger model for data generation can meaningfully improve downstream accuracy; even when the final trained model remains small.
Recently, the FinePDFs dataset was released, with part of its data annotated using RolmOCR, a 7B fine-tuned version of Qwen2.5-VL-7B trained on OlmOCR-mix-0225. Given our results showing that 7B annotators underperform significantly compared to 72B ones, this suggests that FinePDFs could be further improved by using larger models for annotation. It should also be noted that, unlike RolmOCR which excluded headers and footers, we produce full-page transcription, which can include useful information. Our dataset will be released soon to strengthen the ecosystem of open-source multimodal datasets for OCR and document understanding.
Vocabulary Pruning
The Qwen3 language model is a largely multilingual model and thus uses a large multilingual vocabulary of 151,936 tokens, resulting in substantial embedding and LM head weights. For specialized OCR tasks, particularly when focusing on specific languages or document types, most of these tokens are rarely or never used, representing unnecessary model capacity and computational overhead. Thus, we decided to study whether we could prune the vocabulary of the language model without hurting the performance for some languages.
In this part, we focus on French and English documents. Our token frequency analysis and pruning decisions are based on bilingual (French-English) OCR training data. Consequently, our evaluation benchmarks and speed performance measurements are conducted on English documents to assess the effectiveness of this language-specific vocabulary reduction.
We explored reducing the vocabulary to 51k, 32k, and 16k tokens using a frequency-based pruning method that preserves tokenizer integrity:
- Token frequency analysis: We computed occurrence counts for each token across our OCR training dataset, revealing that a large portion of the vocabulary appears infrequently or not at all in document text.
- Recursive frequency scoring: Since BPE tokenizers compose tokens from sub-token units, we cannot simply remove infrequent tokens without breaking the tokenization process. For each frequently used token, we identify all its subsequences that exist as separate tokens in the vocabulary and propagate frequency counts recursively. For example, if "hello" appears 100 times, we add 100 to the counts of constituent sub-tokens like "he", "ell", and "lo". This ensures essential building blocks are retained even if they rarely appear independently.
- Ranking and selection: Tokens are ranked by their combined score (direct frequency + recursive frequency). The pruned vocabulary consists of all special tokens plus the top N highest-scoring tokens to reach the target size.
The embedding and LM head weights are transferred by mapping each retained token to its original embedding vector. BPE merge rules are filtered to include only merges valid under the new vocabulary.
Impact of vocabulary pruning on different languages
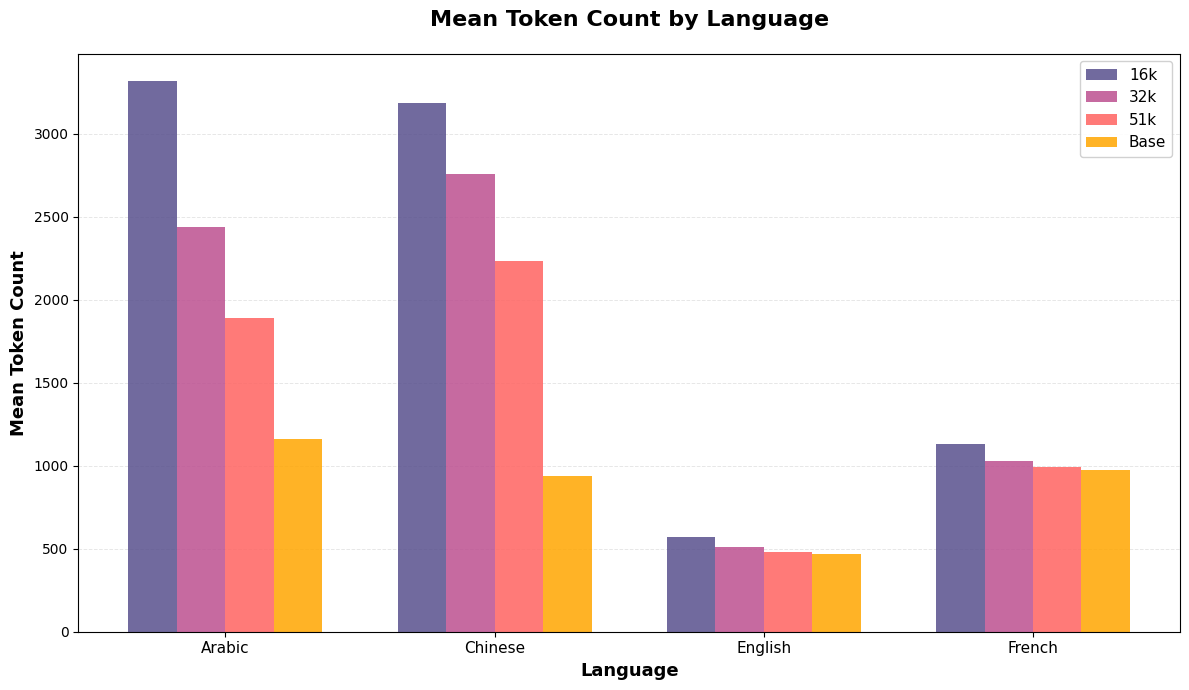
As shown above, vocabulary pruning maintains tokenization efficiency for English and French but severely impacts languages with non-Latin scripts. Arabic and Chinese experience a 3× increase in token count with the 16k vocabulary, as script-specific tokens are removed during frequency-based pruning and text must fall back to byte-level encoding. This validates that vocabulary pruning is effective when target languages are well-defined, but sacrifices multilingual capability.
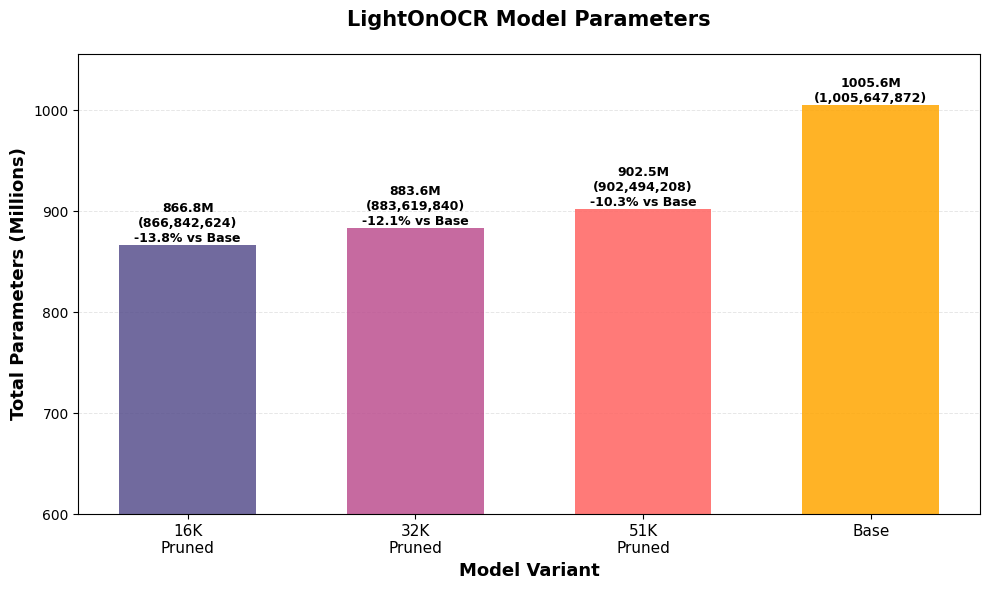
Impact of vocabulary pruning on the sizes
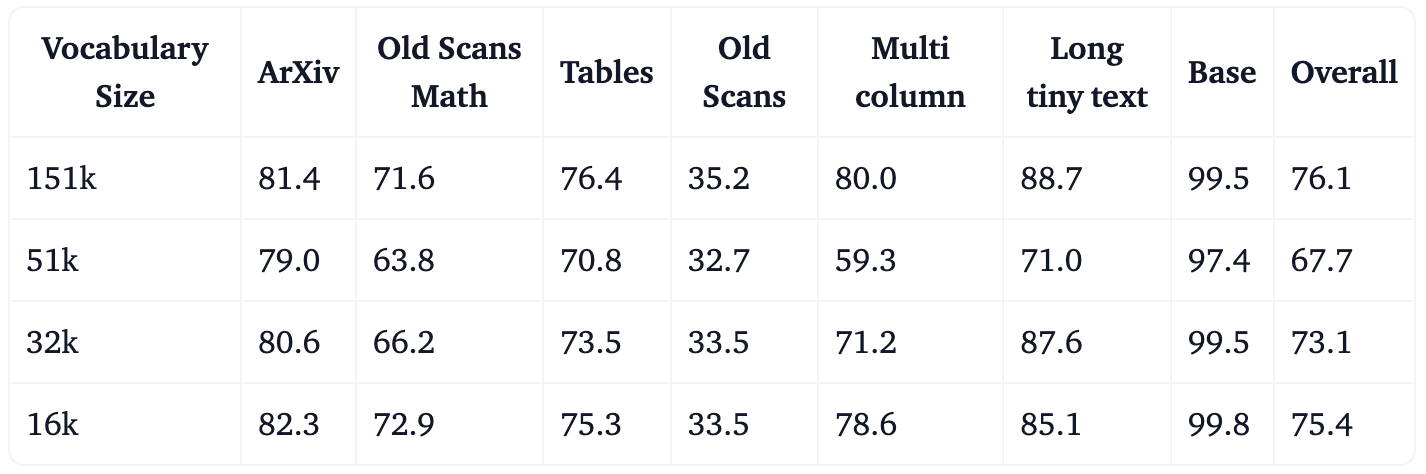
Impact of vocabulary pruning on benches performances
- Olmo-Bench results
- OmniDocBench results (english subset)
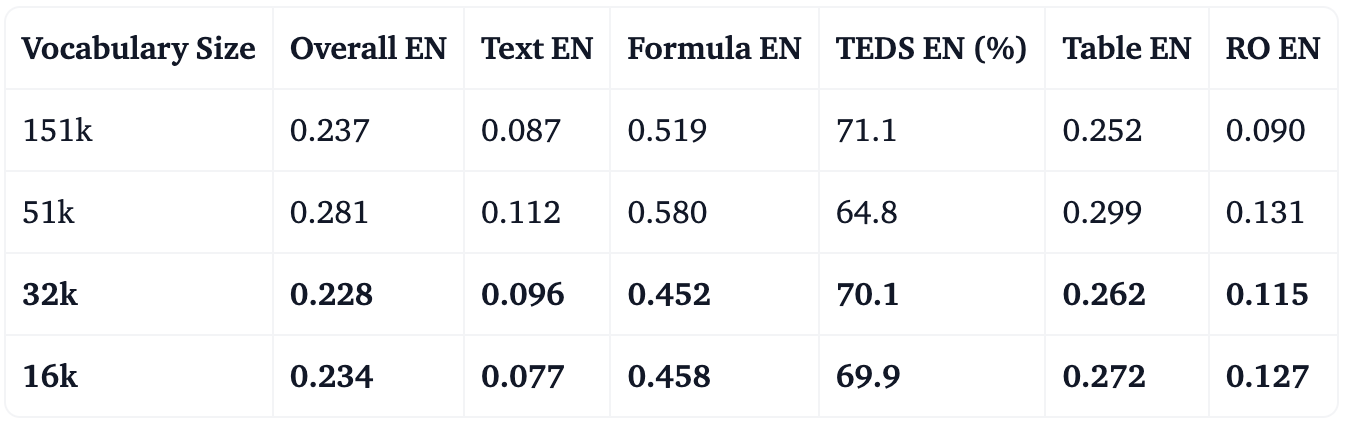
Both benchmarks, evaluated on primarily English documents, show that vocabulary pruning maintains competitive performance. On OLMO, the 16k nearly matches the base model despite using only 10% of the original vocabulary size. On OmniDocBench, the 32k and 16k vocabularies perform comparably to the base model across most metrics.
These results confirm that aggressive vocabulary pruning to 16–32k tokens is viable for targeted language OCR tasks. After highlighting that the vocabulary can be pruned, let’s see how this pruning can further improve the speed of the model.
Impact of vocabulary pruning on the inference speed

Parsing speed measurements (pages/sec) on an English document corpus show that all pruned vocabularies achieve faster inference than the base model. The 32K vocabulary delivers the best speedup, emerging as the optimal compromise between speed and accuracy for English OCR tasks.
The 16K vocabulary shows a smaller speed improvement because the reduced vocabulary size increases the number of tokens per page, partially offsetting the benefits of smaller embedding and LM head matrices. The 32K variant balances vocabulary coverage with reduced model size, achieving the best inference performance.
Image resolution
We use a native-resolution image encoder following the NaViT design, allowing the model to process documents at their original resolution. Since all our data are stored as PDFs, we control the rendering step and fix the DPI at 200 for simplicity. No resizing or complex preprocessing is applied; we only ensure that the rendered image’s maximum dimension does not exceed 1540 pixels for computational efficiency while maintaining aspect ratio.
To understand the impact of image resolution at inference time, we ran an experiment varying the input size during inference. During training, images larger than 1024 pixels on their longest side are resized to 1024, while smaller images are kept at their native resolution.
Table 3. Impact of inference resolution on olmOCR-Bench

As shown in the table above, increasing the resolution at inference time consistently improves performance, especially on documents with dense text or small fonts. Higher-resolution inference proves particularly beneficial for Old Scans Math and Long Tiny Text, though it results in a slight drop in performance on table-heavy subsets.
Data augmentation
We tested light image-level augmentations similar to the Nougat paper to assess their impact on robustness. The goal was to simulate realistic document noise such as small rotations, scaling, grid distortions, and mild morphological operations like erosion and dilation, without affecting readability.
Table 4. Impact of image augmentation on olmOCR-Bench

The differences are small overall. Augmentations slightly improve robustness on noisy or irregular text (e.g. old_scans_math, long_tiny_text), but may reduce accuracy on clean structured subsets. Given the scale and diversity of our dataset, image augmentation does not bring measurable gains but we decide to use it in the final model as it could be a limitation of Olmo-bench having clean documents overall compared to real world.
Finetunability of LightOnOCR and flexibility of our approach
In this section, we want to highlight how easily LightOnOCR can be fine-tuned on domain-specific data, a key advantage over recent complex pipelines that cannot be adapted end-to-end. As an example, we use the OlmOCR-mix-0225 dataset and focus only on the documents subset, excluding books for which the source PDFs are not readily available in the dataset.
To demonstrate adaptability, we start from the pre-trained LightOnOCR weights and fine-tune for a single epoch, with no additional hyperparameter tuning.
Table 5. Finetuning LightOnOCR on OlmOCR-mix-0225 (documents subset)

Fine-tuning on the OlmOCR dataset leads to a clear performance gain, even without hyperparameter tuning. After just one epoch, the model reaches 77.2% overall and over 91% on headers and footers. This brings us already above many competitors such as MonkeyOCR-3B and around the level of MinerU2.5 on the benchmark, and could certainly be improved with further tuning. While not the main objective of our work, this simple fine-tune highlights how easily the model can adapt and confirms its versatility and suitability for further specialization tasks.
This is an important distinction compared to pipeline-based approaches like dots.ocr, MinerU2.5, PaddleOCR, etc. Our model being end-to-end means we can continuously improve and adapt the model to specific data distributions by simply finetuning it, the same can not be said about pipelines where the different moving components would require a separate data annotation step.
OmniDocBench Results and Adaptations
Alongside OlmOCR-Bench, we also evaluated our models —and training approach— on the OmniDocBench benchmark. This section presents our complete results, along with remarks on the evaluation metrics, their sensitivity to formatting, and the tests we conducted to better understand these effects.
Benchmark and adaptations
We study here the performance of our model using OmniDocBench v1.0. A benchmark consisting of 981 PDF pages spanning 9 document types, 4 layout styles, and 3 language categories, divided into English and Chinese subsets. OmniDocBench primarily relies on edit distance as its evaluation metric, which is highly sensitive to formatting and syntax differences.
To ensure compatibility with OmniDocBench’s HTML-based evaluation, we applied a lightweight, regex-based post-processing step that detects Markdown tables and converts them into HTML. This conversion is intentionally minimal and systematic, meaning that it likely underestimates our model’s true performance on table extraction tasks.
Sensitivity to formatting
Although OmniDocBench includes clever adaptations to mitigate formatting bias, it still relies heavily on edit distance—a metric that is highly sensitive to text layout rather than semantic content. Since our model was trained to produce Markdown tables—which we then converted to HTML for the evaluation—we hypothesized that this conversion process might have negatively affected our final scores.
To quantify this effect we therefore provide the results not only for the three models we release today, but also for LightOnOCR-1B-html-tables, a variant of LightOnOCR-1B trained using the same dataset and with identical hyperparameters, except that tables were directly represented in HTML and formulas were slightly simplified. This simple modification led to significant improvement in OmniDocBench scores, yielding an overall English score of 0.168, with notable gains in the formulas and tables categories, as shown below:
Table 6. OmniDocBench scores depending on training dataset format (lower is better except for table TEDS) for English documents
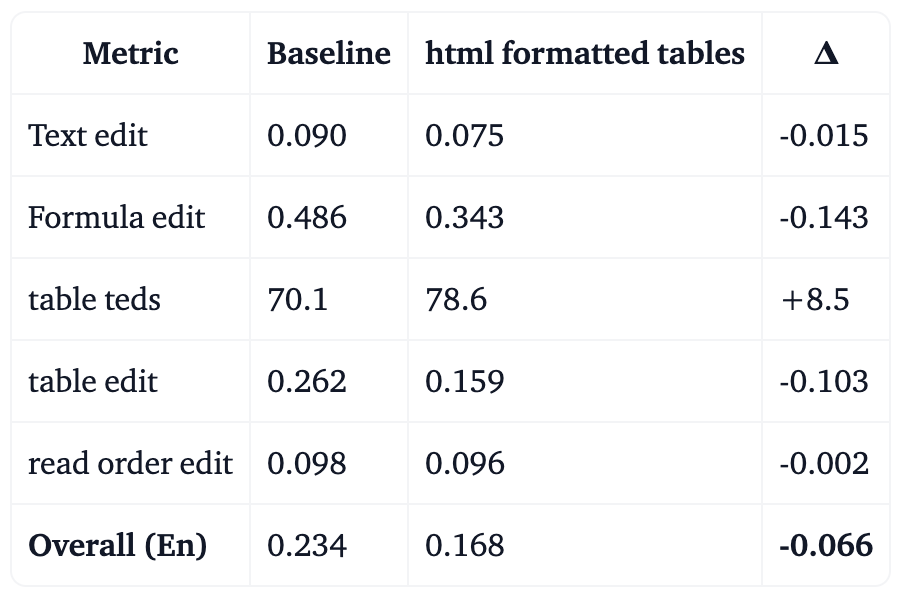
It is worth noting that the conversion from Markdown tables to HTML in our dataset was performed using simple regular expressions. Consequently, our scores on this benchmark could likely be improved further by instructing the teacher model to generate tables directly in HTML. However, since this approach does not align with our preferred output formatting conventions, we do not plan to release this variant.
Results
The table below compares our model’s results with those of competing approaches. Our models achieve substantial improvements over the teacher model, performing on par with GPT-4o on the English subset. As discussed above, the LightOnOCR-1B-html-tables variant further pushes performance, illustrating the high sensitivity of OmniDocBench to output formatting.
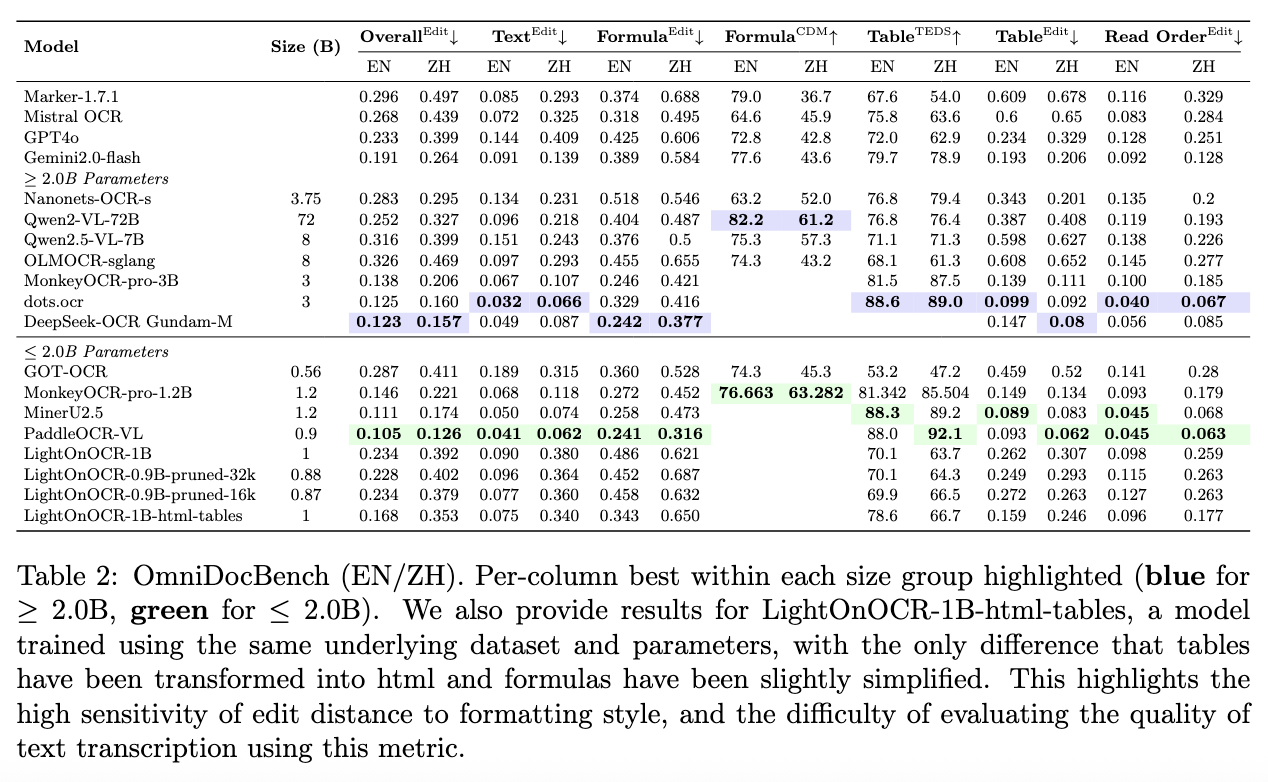
In summary, this experiment underscores the strong sensitivity of edit-distance–based metrics to formatting style and the inherent limitations of using such metrics to assess the true quality of text transcription.
Examples
Example 1: Math dense page

Example 2: Old math Scan

Example 3: Multi-column with tiny text

Example 4: Number-heavy table with repetitions
Conclusion
We introduce LightOnOCR-1B, a vision-language model for OCR that sets a new standard for small and efficient document understanding systems. Trained end-to-end on a large, diverse, and high-quality PDF dataset, it offers a simple, unified system in place of the complex pipelines used in most recent works, allowing to be adapted easily on your specific domains.. Besides the model, we share our insights on how to train an OCR model and the large-scale, diverse and high quality training dataset.
LightOnOCR-1B is fast, open source, and easy to integrate into production. Built with efficiency in mind, it includes a variant with a pruned tokenizer optimized for European languages, achieving up to 12% faster decoding compared to full vocabulary. Integrated with vLLM, it offers high-throughput serving and simple end-to-end trainability; improving the model only requires better data.
Links:
Compute grant
This work was granted access to the HPC resources of IDRIS under the allocation 2025-AS011016449 made by GENCI, enabling us to use the Jean Zay supercomputer.
Citation
@misc{lightonocr2025,
title = {LightOnOCR-1B: End-to-End and Efficient Domain-Specific Vision-Language Models for OCR},
author = {Said Taghadouini and Baptiste Aubertin and Adrien Cavaillès},
year = {2025},
howpublished = {\url{https://huggingface.co/blog/lightonai/lightonocr}}
}
.png)


.avif)
.avif)
