.svg)


TL;DR
Throughout 2024 and early 2025, much of the industry conversation focused on long context windows. Some argued that models with 100K, 1M or even 2M tokens would make RAG unnecessary. But this debate misses the real issue.
The real question for enterprises is not whether RAG is dead. It is how relevant information is added to your context in the first place.
There are two ways to feed information to your AI system. One is to rely on long context models and send entire documents into the prompt, hoping the model will identify the right pieces. This method is expensive, slower and often less accurate. The other is to use a structured retrieval system built on a vector database that performs targeted lookups, keeps token usage under control and produces more reliable grounding.
Once you compare both approaches on real enterprise workloads, the difference becomes clear. Long context forces you to pay for hundreds of thousands of unnecessary tokens per request. A retrieval system returns only what matters, at a fraction of the cost and latency.
And that’s assuming models are actually able to focus on their entire context! For a deeper breakdown of this shift, we recommend reading Amélie Chatelain’s analysis here:
👉 RAG is Dead, Long Live RAG: Retrieval in the Age of Agents
The numbers highlight the same conclusion across workloads. Enterprise AI always depends on retrieval, but only efficient retrieval delivers sustainable economics. The architecture you select at the retrieval layer directly shapes the cost, speed, accuracy and ROI of your AI strategy.
1. Long Context vs RAG: The Cost Breakdown Enterprises Needed
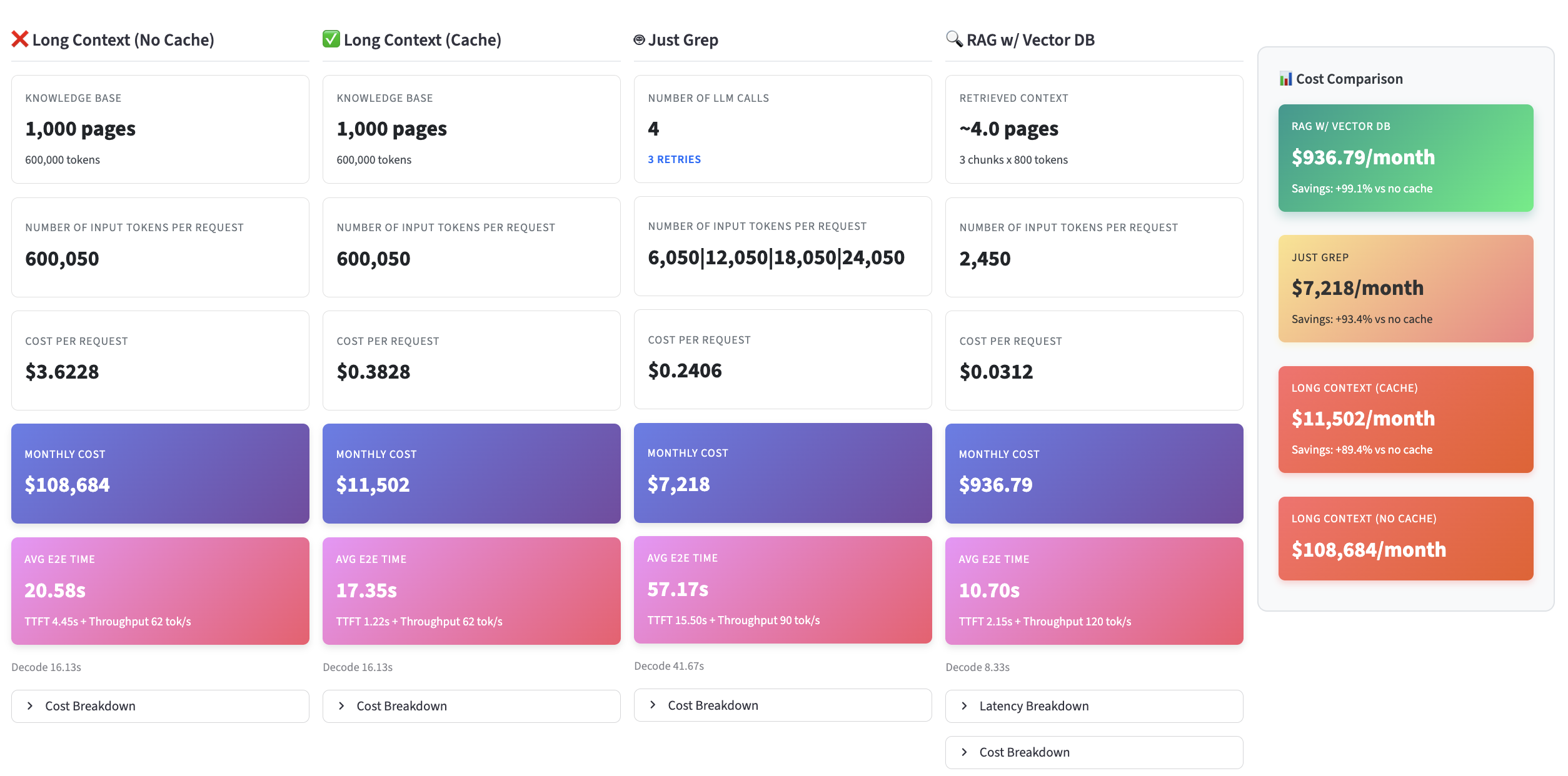
To evaluate realistic usage, we tested a typical enterprise scenario:
• 1,000 pages knowledge base (around 600K tokens)
• 1,000 requests per day
• 4 knowledge base updates per month
• Real LLM pricing (Anthropic Claude Sonnet)
The calculator compares four strategies:
- Long context (no cache) → “Dump everything in the prompt.”
Used by basic ChatGPT/Claude workflows without retrieval. - Long context (cached) → Reuse context blocks to reduce cost.
Used by many SaaS copilots and agent platforms. Note that managing cache updates can be challenging, if your knowledge base changes frequently - grep / lexical brute force → Keyword search only.
Used by tools like Claude Code; great for code and generally on text-only files, fails on PDFs/diagrams. - RAG + vector database → Retrieve only what matters (text, PDFs, tables, diagrams).
Used by modern enterprise AI platforms, including LightOn.
Try the Calculator and Benchmark Your Own Workload
Long context surely killed RAG - Calculator
Adjust:
• knowledge base size
• number of requests
• update frequency
• model type
• caching strategy
You will see how retrieval architecture shapes cost and performance.
Monthly Cost Comparison
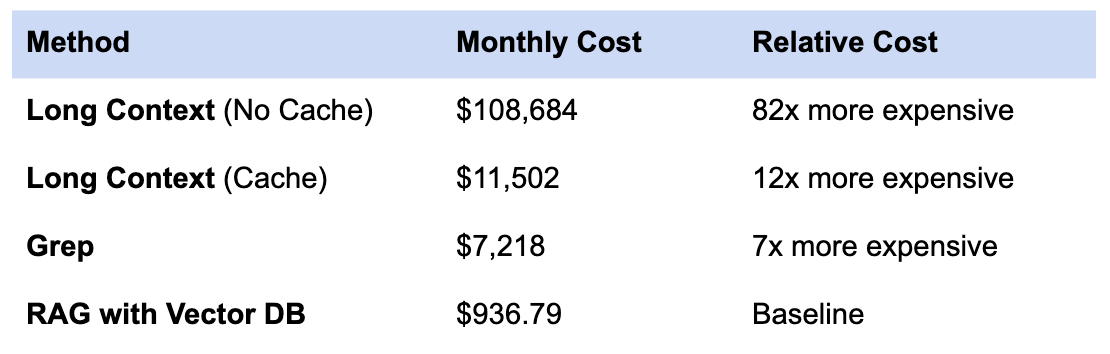
✔ RAG is 8x to 82x cheaper than long context
✔ RAG delivers around 2x faster latency
✔ RAG improves accuracy on multimodal and complex documents
This is why enterprises who test long context often come back to retrieval. The economics do not scale.
2. Why Long Context Windows Become Expensive and Unreliable
Large context windows look powerful until they deal with real enterprise data.
A large context multiplies token costs
Most queries require only a small amount of information. Long context approaches:
• force the model to process irrelevant content, increasing noise
• increase compute cost
• inflate latency
It is like paying ten people to attend a meeting when only one has the answer.
A larger context does not guarantee better comprehension
Research shows:
• performance degrades as context length grows
• noise overwhelms signal
• attention weakens on long inputs
• diagrams and images blow up token counts
One million tokens is not large when:
• a technical diagram counts for at least 1,000 tokens
• typical codebases reach tens of millions of tokens
• enterprise repositories contain hundreds of millions of tokens: remember, 1,000 document pages in our knowledge base was already ~600k tokens! 1,000 pages really isn’t that much.
Long context increases cost without improving the quality of retrieval.
3. Why Grep Fails When Enterprise Knowledge Is Multimodal
Lexical tools like grep excel on text content, which is why they are particularly adapted for code retrieval. They fail on enterprise knowledge because most information is spread across PDFs, tables, diagrams, PowerPoint decks and scanned documents.
A simple industrial query shows the limitation:
“Which components sit above the casing hanger?”
The answer exists as a visual relationship. There is no keyword for grep to match. Grep cannot interpret diagrams or spatial organization.
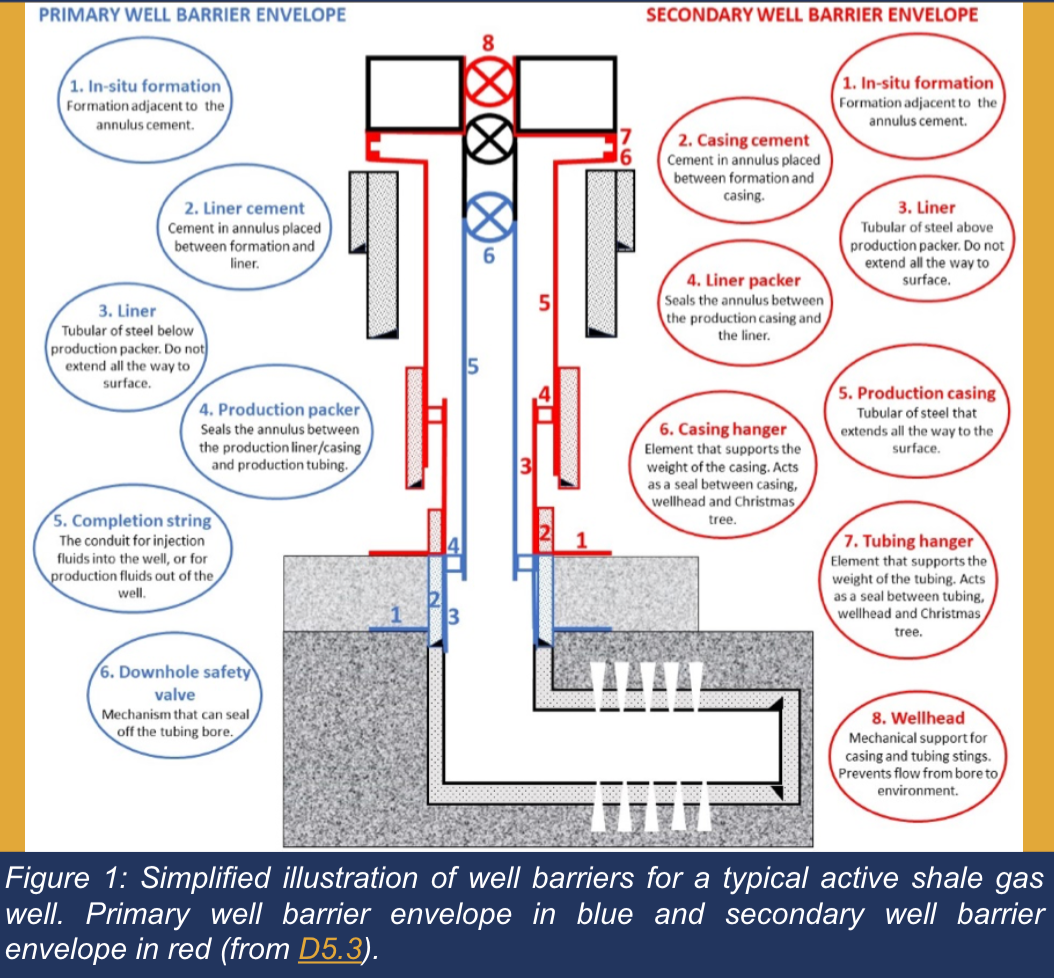
Modern enterprise information retrieval requires multimodal retrieval that can understand:
• semantic meaning
• diagrams and spatial structure
• visual signals
• hybrid lexical and semantic patterns
LightOn Enterprise Search was built for this multimodal reality.
4. RAG Evolved: Intelligent Retrieval for Agentic AI Systems
Modern RAG is a conditional decision framework:
- When retrieval is necessary
- What to retrieve
- Where to retrieve from
- How to combine context efficiently
Poor retrieval increases hallucinations and cost. Intelligent retrieval improves accuracy, speed and reliability.
5. LightOn Enterprise Search: Retrieval Built for Accuracy, Cost Control and Sovereignty
LightOn Enterprise Search transforms retrieval into a sovereign, multimodal and intelligent pipeline.
Learn more about it here:
LightOn Sovereign & Multimodal Search
Key Capabilities
✔ Multimodal retrieval across text, diagrams, tables and images
✔ Vision aware reranking to select the right diagram or page
✔ Sovereign deployment on prem or sovereign cloud
✔ Lower token usage for predictable cost
✔ Compatible with agentic workflows
✔ Better grounding and fewer hallucinations
This is retrieval designed for real enterprise production environments.
Conclusion: Retrieval Is the Foundation of Enterprise AI ROI
Enterprise AI cannot scale without efficient retrieval.
Long context can help in specific cases, but it cannot solve:
• cost explosion caused by large prompts
• noise from unfiltered context
• failure of lexical tools on diagrams or visual content
• requirements of sovereign or on prem environments
Every mature AI system reaches the same conclusion.
The quality of retrieval determines the quality, speed and cost of AI.
With LightOn Enterprise Search, retrieval becomes:
• precise
• cost efficient
• multimodal
• sovereign
• production ready
If enterprises want AI that delivers measurable value, retrieval is where the value begins.
👉 Want to see how intelligent retrieval transforms your AI use cases? Contact us


.avif)
.avif)