
.svg)

TL;DR
Every RAG demo works.
Production is where most of them fail.
Connecting a large language model to a small, curated set of documents is easy. The answers are fluent, the experience is impressive, and early feedback is overwhelmingly positive. The problems start when RAG leaves the demo environment.
At scale, reality looks very different:
- millions of documents
- multiple heterogeneous data sources
- continuous updates and versioning
- users with different access rights and responsibilities
- This is where most RAG systems begin to degrade.
Answers become outdated, relevance drops, latency increases and trust erodes.
At that point, the usual diagnosis misses the mark. The issue is rarely the model. Modern LLMs are already capable enough. What fails in production is the data infrastructure underneath, originally designed for controlled demos, not for the operational complexity of real enterprises.
RAG does not fail because it cannot generate. It fails because it cannot retrieve and maintain knowledge reliably at scale.
Why Most RAG Pipelines Break in Production
From the outside, most RAG architectures look similar but from the inside, they collapse for very predictable reasons.
Snapshot ingestion instead of continuous extraction
Most pipelines ingest data once, or periodically, as a batch.
The result: answers that are technically correct, but operationally obsolete. In fast-moving organizations, stale knowledge is worse than missing knowledge.
Fragile trust at scale
When users receive one wrong or outdated answer, confidence drops and when it happens repeatedly, the adoption stops. At scale, relevance errors are not edge cases, they are systemic.
Security becomes a blocking issue
RAG systems that ignore access control or apply it loosely are quickly flagged by security teams. If retrieval does not strictly respect permissions, the project never reaches production.
Latency and cost explode
What works on a few hundreds documents breaks on thousands. Indexing strategies, chunking choices, and retrieval layers that seemed “good enough” suddenly become bottlenecks. This pattern consistently points to a deeper architectural issue.
RAG is not a feature. It is infrastructure.
Most enterprise RAG projects are treated as product features: a retrieval layer added on top, with the expectation that it will behave like any other application capability. This framing is one of the main reasons RAG systems fail when they reach production.
RAG is infrastructure. It sits below AI applications and directly inherits all enterprise constraints:
- Scale
- Heterogeneous data
- Security
- Governance
- Continuous change
Architectures designed as features may work in isolation, but they break under real operational conditions.
This distinction matters because infrastructure must be reliable by default, observable in production, and secure at all times. In RAG systems, the generation layer often receives the most attention, but the “G” in RAG only amplifies what the “R” provides. When retrieval is incomplete, outdated, or misaligned with access controls, generation will confidently produce incorrect or unsafe results.
Production-grade RAG therefore requires a shift in mindset: not how to add RAG to an application, but how to build and operate a retrieval and data extraction layer that can sustain AI workloads over time.
The constraints that break RAG at scale
When RAG systems fail in production, the causes are rarely spectacular. Degradation is gradual, relevance drops, answers age and trust erodes. In most enterprise deployments, these failures come from a small set of structural constraints that are consistently underestimated.
Static data assumptions
Many RAG pipelines rely on one-time ingestion or periodic batch updates. This assumes that enterprise data is relatively stable. It is not. Documents are updated, procedures are replaced, and new versions appear continuously.
When extraction is not synchronized with these changes, retrieval diverges from operational reality. The system still answers, but on outdated knowledge. At scale, stale answers are worse than missing ones.
Multimodal data and chunking
Early RAG setups work on clean text. Production does not. Enterprise knowledge lives in scans, PDFs, spreadsheets, presentations, images, and complex documents.
Without OCR and proper preprocessing, large parts of the data remain invisible. Chunking adds another failure mode. Too small, and context is lost. Too large, and relevance collapses. Chunking is not a tuning parameter. It is an architectural decision.
Access control and traceability
Access control is where many RAG projects stop. Vector search systems do not understand enterprise permissions. If access constraints are not enforced at query time, the system is unsafe.
Traceability matters just as much. Enterprises need to know where an answer comes from, which documents were used, and which version was retrieved. Without this, trust does not survive production.
Among these constraints, static ingestion is often the first point of failure.
From Static Ingestion to Continuous Extraction in RAG Systems
Most RAG pipelines are built around ingestion. Very few are built around continuous extraction.
Enterprise data is alive:
- documents are updated
- new versions appear
- access rights change
- content grows incrementally
Treating extraction as a one-off setup guarantees failure. A production-grade RAG architecture requires a pipeline that is:
- continuous
- observable
- resilient
- governance-aware
This pipeline is not a feature, it’s a long-lived system, evolving alongside the organization.
Security, Access Control, and Trust Are Not Optional
Enterprise RAG does not exist without governance.
Access control must be enforced at query time, not retrofitted later.
If a system returns the right answer to the wrong user, it creates risk, not value.
Traceability matters just as much:
- Where does this answer come from?
- Which documents were used?
- Which version?
Without clear answers, RAG systems fail security reviews and lose user trust.
In enterprise environments, trust is not emotional but structural.
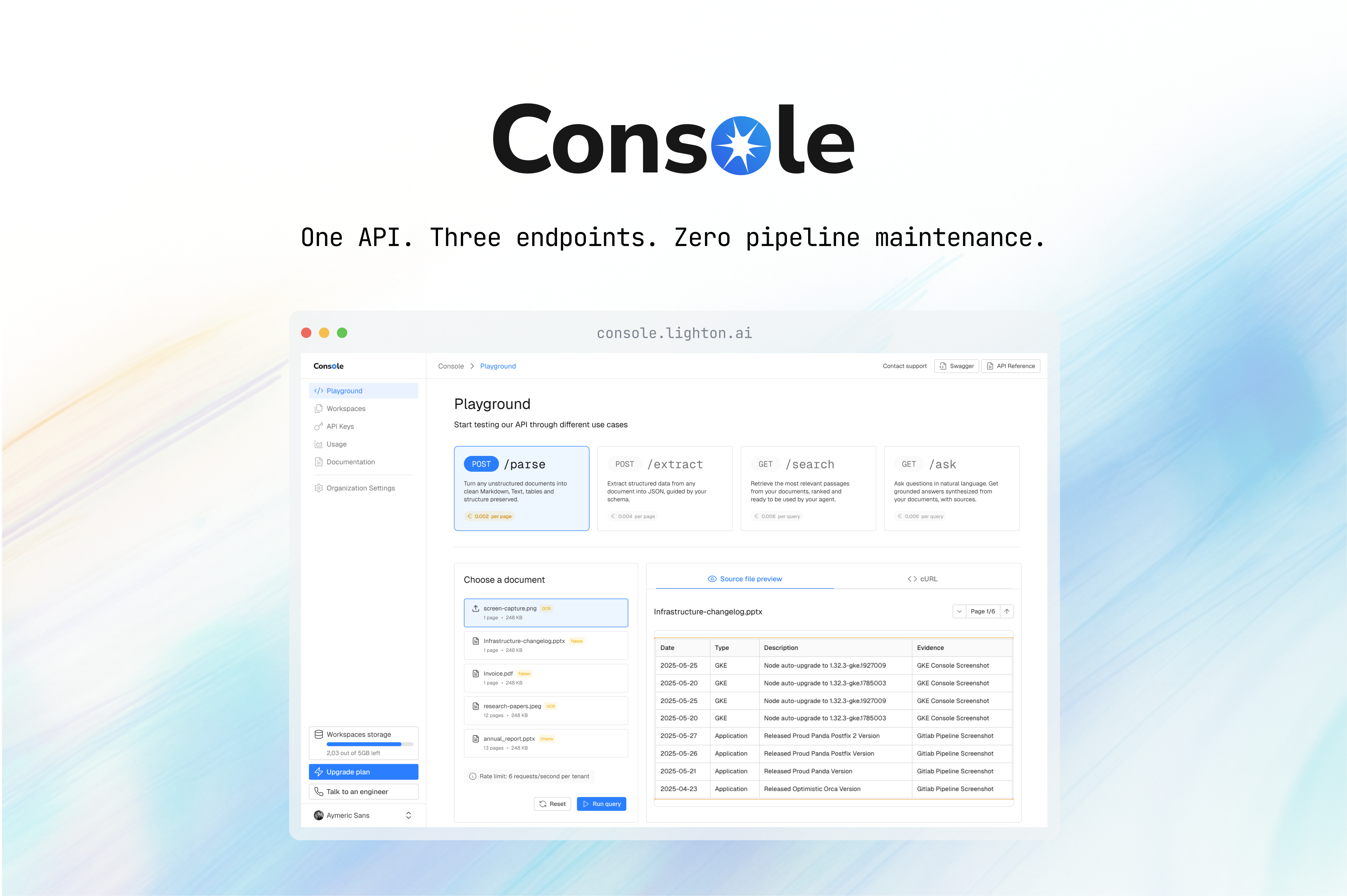
How LightOn Builds RAG Infrastructure for Production, Not Demos
LightOn was built around a simple observation: enterprise AI only works if search and extraction work first.
The platform is designed as infrastructure, not as an assistant:
- continuous data extraction across formats
- native OCR and preprocessing
- semantic chunking aligned with enterprise documents
- large-scale vector indexing
- strict role-based access control enforced at query time
- reranking for precision and trust
- deployment under sovereignty and compliance constraints
Search is not an add-on. It is the backbone.
By placing continuous extraction at the core, LightOn enables RAG systems that remain accurate, secure, and usable as they scale from pilots to production.
If you want to stop building RAG demos and start Building RAG Infrastructure 👉 Let’s talk


.avif)
.avif)
