.svg)


TL;DR
ModernBERT continues to shake up the Transformers landscape, after revolutionizing encoder-only models for retrieval and classification, its breakthrough training recipe and architecture, plus a new open-source dataset, has now been applied to decoder-only models. The result? Models that outperform Llama 3.2 1B and SmolLM 2.
For the first time, we have both encoder- and decoder-only models, spanning 17M to 1B parameters, trained with identical data (2T tokens), architectures, and recipes, enabling true apples-to-apples comparisons of masked language modeling (MLM) and causal language modeling (CLM) objectives.
Ettin sets a new state-of-the-art for open-data models in both categories and opens the door to further explore whether a competitive encoder can be built from a decoder, and vice versa.
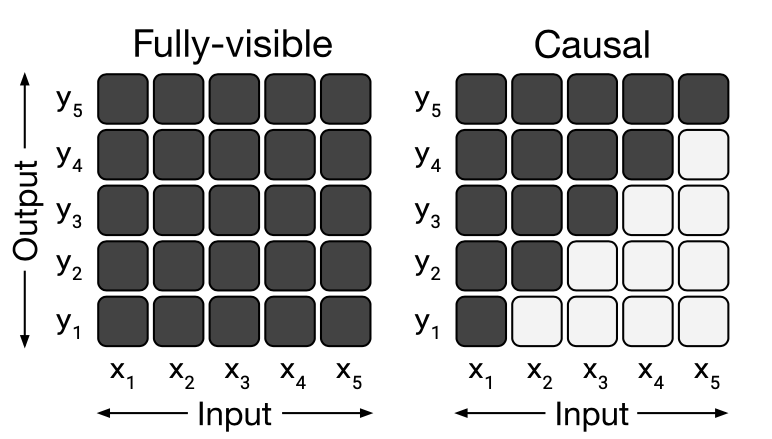
Encoders vs Decoders: The Architecture Divide
The LLM community has largely converged on decoder-only models like GPT, Llama, and Qwen. Their generative capabilities are impressive, but this focus has forgotten about earlier categories such as encoder-only models like BERT.
For classification, retrieval, and embedding tasks, encoder-only models like BERT remain the workhorses of production systems. They're faster, more memory-efficient, and often more accurate for discriminative tasks. The key difference lies in their attention patterns:
- Encoder models use bidirectional attention, allowing each token to "see" all other tokens in the sequence (fully visible)
- Decoder models use causal attention, where tokens can only "see" previous tokens to enable autoregressive generation
Yet while decoder models have seen rapid innovation, encoder model development had stagnated -- until recently with efforts like ModernBERT to update them. But which architecture is better? Previous comparisons between encoders and decoders were limited by different datasets, architectures, and training recipes.
Named after the two-headed Norse giant, Ettin provides a controlled comparison by training with both architectures on identical data, identical model shapes, and identical training recipes. They only differ in attention patterns and training objectives!
Training Recipe: Modern Techniques for Both Architectures
We build on the ModernBERT recipe which used modern decoder-only techniques, providing a strong base for training both architectures.
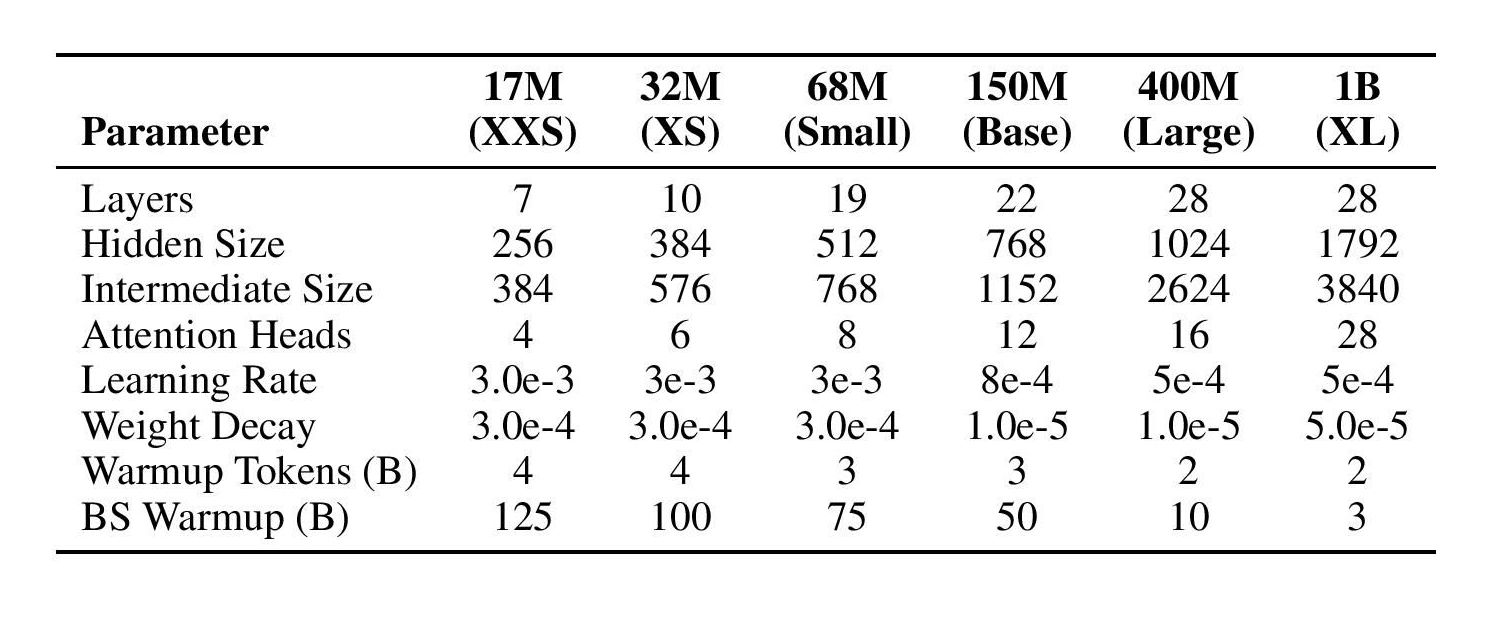
Sizes
We train six different sizes, ranging from 17m to 1B. This allows us to test the effects of scale and provides a wide variety of models so you can use whether you need a blazing fast on-device model or a powerful but slower model.
Three-Phase Training Process
We use a comprehensive three-phase training approach to maximize performance:
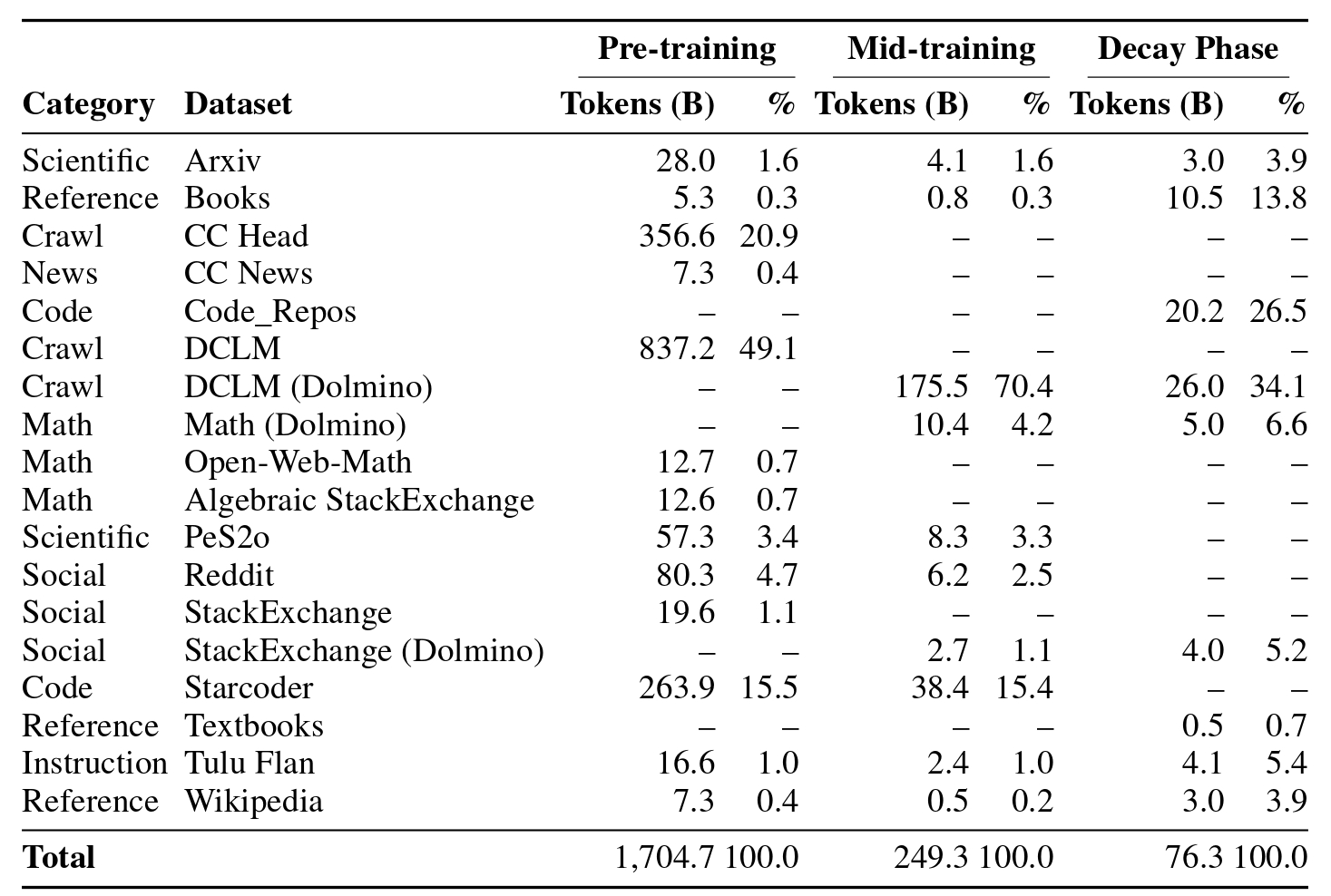
Phase 1 - Pre-training (1.7T tokens): We start with a diverse mixture of high-quality data sources, training on shorter contexts (1024 tokens) to establish strong foundational knowledge.
Phase 2 - Context Extension (250B tokens): We increase context length to 8K tokens using higher-quality filtered data, allowing models to understand longer documents and more complex relationships.
Phase 3 - Decay (100B tokens): We finish with premium data sources including scientific papers, textbooks, and curated content while gradually reducing the learning rate.
Modern Architecture Components
Our models gain all the benefits of ModernBERT's speed, allowing them to be significantly faster than the previous generations of encoders.
Data Sources and Quality
Unlike ModernBERT, all our training data is public and reproducible:
You can continue train these models on new data or propose a new recipe to further improve results!
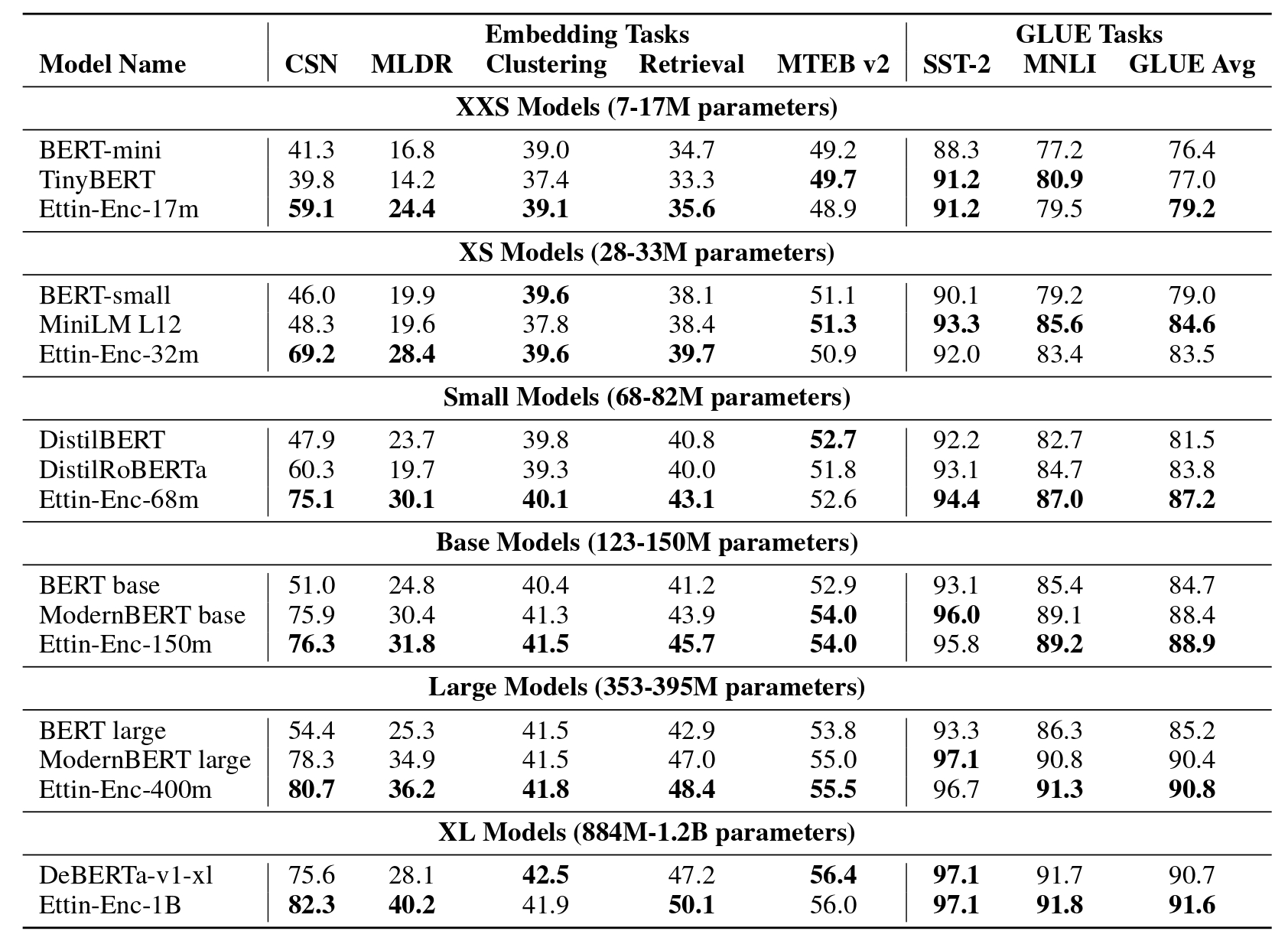
Encoder Results: Beating ModernBERT
Our encoder models outperform ModernBERT across all tasks and model sizes, while using completely open training data. Since we provide a large range of sizes, you can now use ModernBERT-style models in smaller sizes (great for on-device or for fast-inference) or power up with a 1B-sized encoder that crushes the competition.
Decoder Results: Beating Llama 3.2 and SmolLM2
Applying the same recipe to decoder models yields equally impressive results, with our models outperforming established baselines such as Llama 3.2 and SmolLM 2:
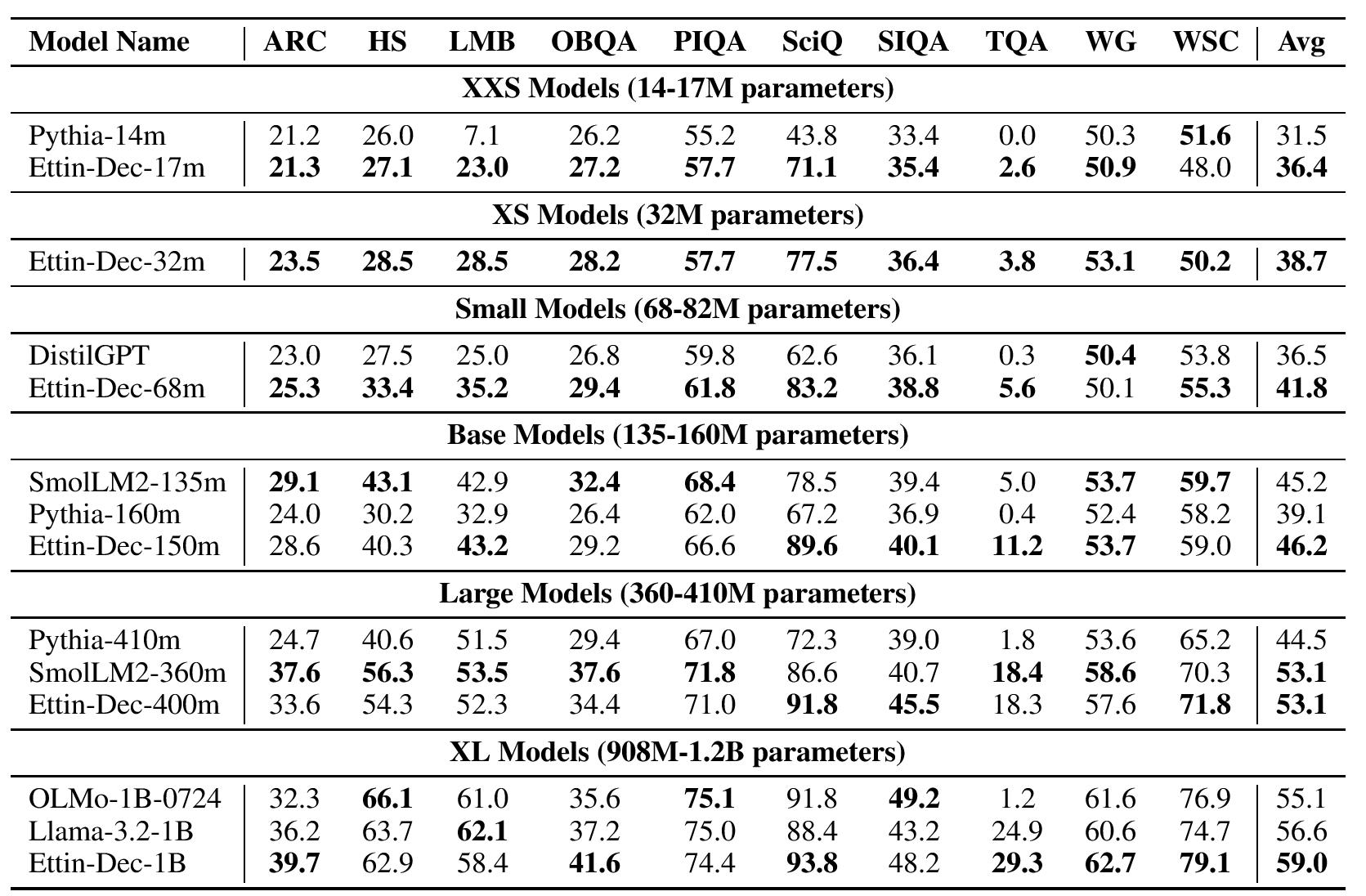
The gains are particularly strong on knowledge-intensive tasks like SciQ, reflecting the benefits of our high-quality training data mixture. These results demonstrate that our training recipe creates genuinely strong models in both architectural paradigms.
Fair Fight: Encoders vs Decoders on Even Ground
For the first time, we can fairly compare encoder and decoder architectures trained with identical data and recipes. The results reveal fundamental architectural advantages that persist even when all other factors are controlled:
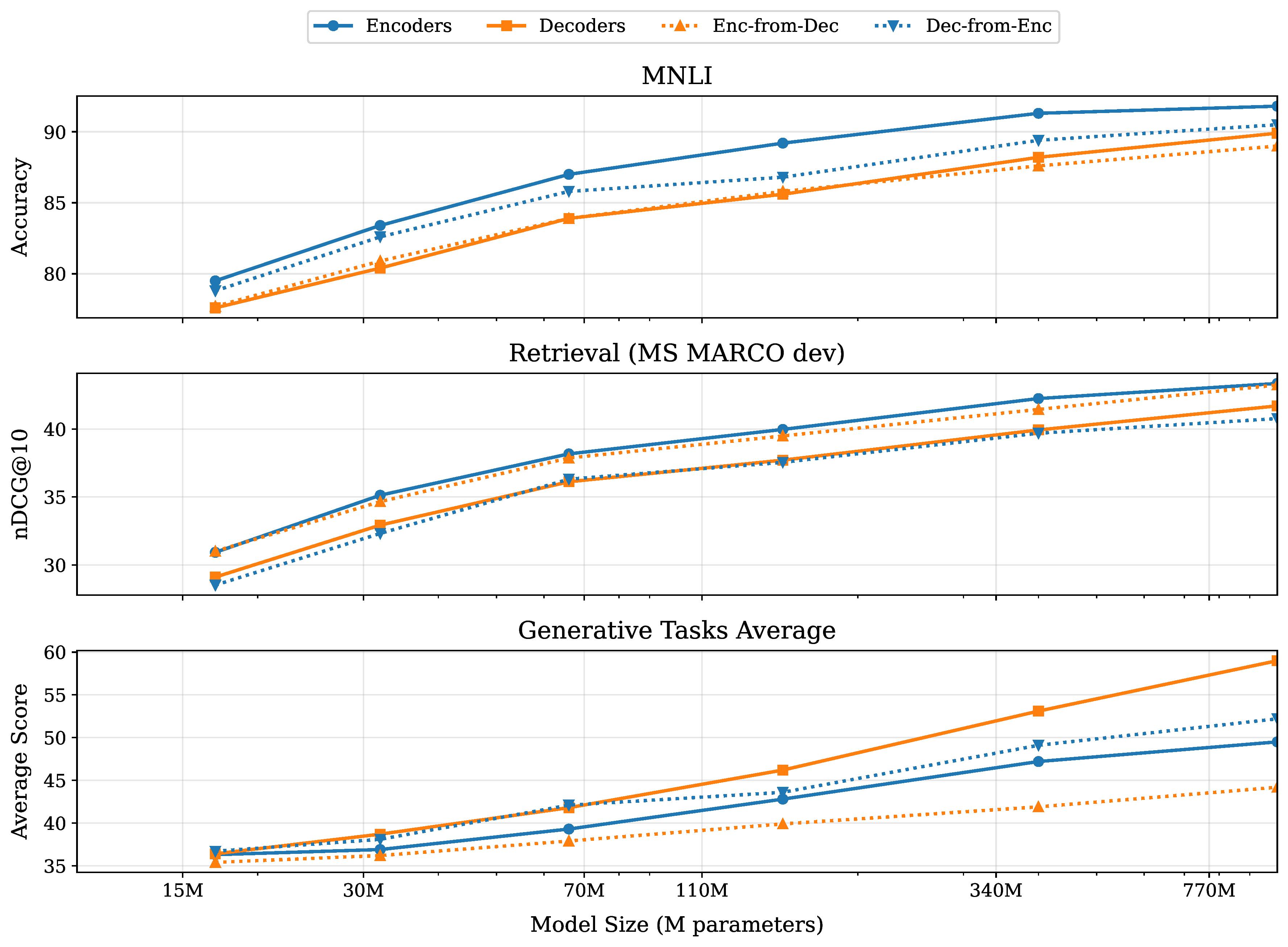
Architecture-Specific Advantages Persist
The results show clear patterns:
Encoders dominate classification and retrieval: On MNLI classification, even a 150M encoder (89.2) outperforms a 400M decoder (88.2). For retrieval tasks, the gap is even larger.
Decoders excel at generation: On generative tasks, decoders maintain consistent advantages, with the performance gap actually widening at larger model sizes.
Size doesn't always matter: A 400M encoder beats a 1B decoder on classification tasks, while a 400M decoder beats a 1B encoder on generation tasks.
Cross-Objective Training Falls Short
Due to the lack of new encoder models, works like LLM2Vec have proposed continue pre-training decoders with MLM. We can now test the effectiveness of this strategy!
We switched the objective and continue trained our models with the opposite objective for 50B additional token. However, we found that:
- Encoder-from-decoder: Still trails native encoders on classification/retrieval
- Decoder-from-encoder: Significantly worse than native decoders, especially at larger scales. This may be because the encoders were trained with MLM instead of MNTP (masked next token prediction) as proposed by LLM2Vec.
This suggests the architecture choice matters fundamentally, not just the training objective.
Beyond Performance: Understanding Model Behavior
With identical training data, we can study how different objectives affect learning. For example, analyzing gender bias using the WinoGender benchmark reveals:
- Encoder models prefer gender-neutral pronouns more often (60%+ neutral vs 30%+ for decoders)
- Both architectures show male bias, but decoders slightly more so
- Cross-objective training affects bias patterns in measurable ways
This opens doors for systematic studies of how training objectives influence model behavior beyond just accuracy metrics.
Usage Examples
You can use these models with just a few lines of code!
For classification and retrieval tasks, use encoder models: You may want to use a fine-tuned version for these tasks as well.
from transformers import AutoTokenizer, AutoModel
# Load encoder for classification/embeddings
tokenizer = AutoTokenizer.from_pretrained("jhu-clsp/ettin-encoder-150m")
model = AutoModel.from_pretrained("jhu-clsp/ettin-encoder-150m")
def predict_masked_token(text):
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# Get predictions for [MASK] tokens
mask_indices = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)
predictions = outputs.logits[mask_indices]
# Get top 5 predictions
top_tokens = torch.topk(predictions, 5, dim=-1)
return [tokenizer.decode(token) for token in top_tokens.indices[0]]
# Example
masked_text = "The capital of France is [MASK]."
predictions = predict_masked_token(masked_text)
print(f"Predictions: {predictions}")For text generation tasks, use decoder models:
from transformers import AutoTokenizer, AutoModelForCausalLM# Load decoder for generationtokenizer = AutoTokenizer.from_pretrained("jhu-clsp/ettin-decoder-150m")model = AutoModelForCausalLM.from_pretrained("jhu-clsp/ettin-decoder-150m")# Generate textprompt = "The future of artificial intelligence is"inputs = tokenizer(prompt, return_tensors="pt")outputs = model.generate(inputs.input_ids, max_length=50, temperature=0.7)generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)Model Family and Links
The complete Ettin suite includes models at six different scales (for both encoders and decoders):
Standard Models:
- ettin-encoder-17m / ettin-decoder-17m (17M params)
- ettin-encoder-17m / ettin-decoder-17m (32M params)
- ettin-encoder-17m / ettin-decoder-17m (68M params)
- ettin-encoder-150m / ettin-decoder-150m (150M params)
- ettin-encoder-400m / ettin-decoder-400m (400M params)
- ettin-encoder-1b / ettin-decoder-1b (1B params)
Research Resources:
- 🤗 Ettin Model Collection
- 📝 Paper
- 🗂️ Training Data (2T+ tokens, fully open)
- 💻 GitHub Repository
- 📊 250+ Training Checkpoints for studying training dynamics or knowledge learning


.avif)
.avif)