.svg)


TL;DR
LightOn integrates into Paradigm a technology that beats the world state of the art: LightOnOCR-2, capable of uncovering and structuring the information buried in all enterprise documents, including the most complex. This is the first of three phases “Bleu, Blanc, Rouge” that widen the gap between Paradigm and the rest of the market.
Until now, the most critical enterprise documents such as sensitive contracts, technical files, regulatory archives have remained largely inaccessible to AI. Too complex, too sensitive, too voluminous. LightOn now makes it possible to exploit them, wherever they already reside.
With one billion parameters, LightOnOCR-2 outperforms every competing model on the OlmOCR benchmark, including those nine times its size. World's best model for document intelligence, LightOnOCR-2 is compact enough to be deployed on-premise, where the documents are. Its end-to-end architecture replaces traditional OCR pipelines and enables scaling.
Technical deep dive
We’re releasing LightOnOCR-2-1B, our second-generation 1B-parameter, end-to-end vision-language OCR model optimized for state-of-the-art conversion of document pages (PDF renders) into clean, naturally ordered text without relying on multi-stage pipelines. Alongside transcription, it can also output bounding boxes for embedded figures/images for workflows that need lightweight layout cues. LightOnOCR-2 is released under the Apache 2.0 license, together with a small family of open-weight checkpoints (OCR-focused and bbox-capable variants, plus base checkpoints) that can be used by the community for fine-tuning, domain adaptation, and layout-oriented applications.
Quick hits:
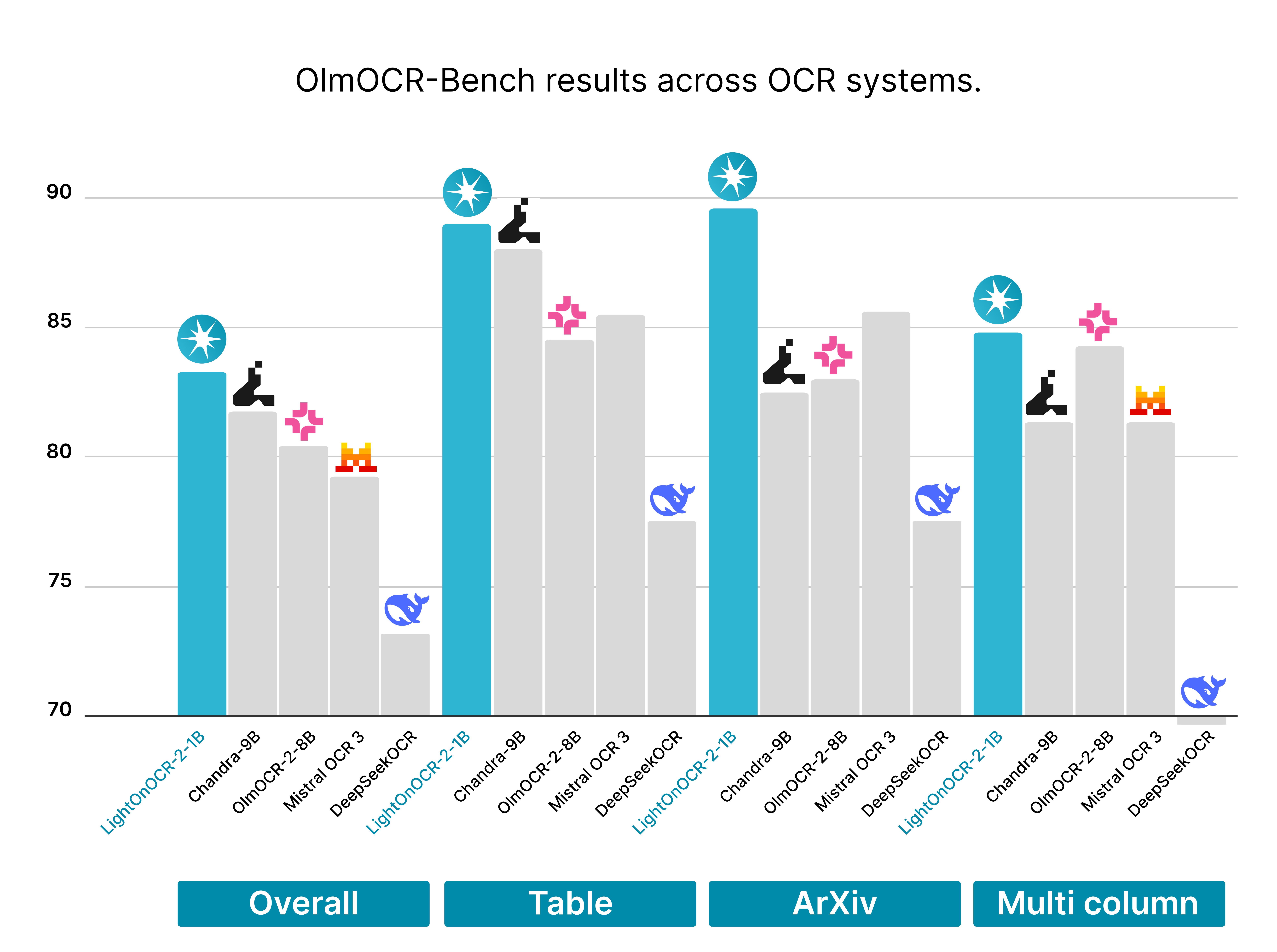
- Better OCR: LightOnOCR-2-1B improves substantially over our first version LightonOCR-1B-1025 and is now State-of-the-art on OlmOCR bench, outperforming Chandra-9B by more than 1.5 percentage points overall, while being close to 9 times smaller, and without relying on pipelines.
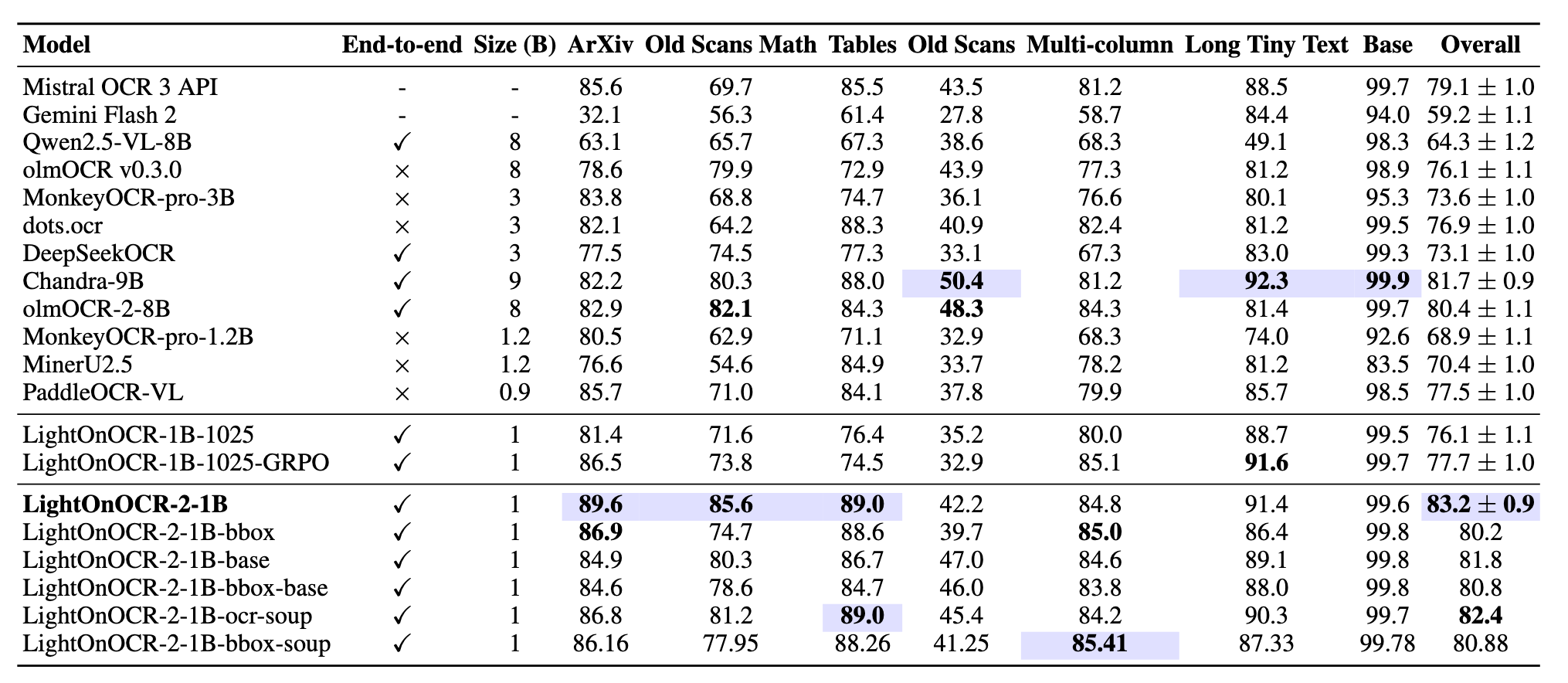
- Speed: 3.3× faster than Chandra OCR, 1.7× faster than OlmOCR, 5× faster than dots.ocr, 2× faster than PaddleOCR-VL-0.9B, 1.73× faster than DeepSeekOCR
- Model family: we’re also releasing additional checkpoints, including bounding-box variants (for embedded image localization) and base checkpoints intended for fine-tuning / merging / post-training recipes.
- Training datasets: We release two open annotations datasets used during training:
lightonai/LightOnOCR-bbox-mix-0126comprising of more than 23M high quality annotated document pages, andlightonai/LightOnOCR-bbox-mix-0126made of close to 500k high quality annotations including bounding boxes for figures and images.Full technical details will be in the preprint, stay tuned for its imminent release!
Links
- Models:
LightOnOCR-2-1B(default; OCR-only, best transcription)LightOnOCR-2-1B-bbox(bbox-focused; OCR + embedded image localization)LightOnOCR-2-1B-ocr-soup(tradeoff checkpoint combining OCR + bbox strengths)LightOnOCR-2-1B-base(base checkpoint, OCR-only; for fine-tuning / merging)LightOnOCR-2-1B-bbox-base(base checkpoint with the capability of outputing image bounding boxes; can be used as a base for RLVR training)LightOnOCR-2-1B-bbox-soup(merged bbox variant. Merges OCR-focused RLVR gains into the bbox model, balancing OCR quality and image localization.)
- Datasets:
lightonai/LightOnOCR-mix-0126lightonai/LightOnOCR-bbox-mix-0126LightOnOCR-bbox-bench: Benchmark for evaluating image localization in documents.
- v1 blogpost
- Preprint: Coming (very) soon!
Capabilities
LightonOCR-2-1B shows significantly improved overall performance, thanks to better annotation quality, consistency, and scale; a more diverse dataset focused on European languages with an increased emphasis on scans and robustness to image degradation; and dedicated procedures to reduce looping.We provide here some selected examples of transcription for LightOnOCR-2-1B, LightOnOCR-2-1B-bbox and for reference our first version model LightOnOCR-1-1025.
Try it out with your own documents on our demo playground!
Key benchmarks
Transcription quality
Main results. LightOnOCR-2-1B scores 83.2 ± 0.9 on OlmOCR-Bench — the best among the systems we evaluated — while using only 1B parameters. The improvements are consistent across categories, with standout gains on ArXiv, old scans with math, and tables, driven by a cleaner/larger training mix, stronger scientific coverage, and higher-resolution training.
Speed
LightOnOCR is designed to fit into large-scale production document pipelines, where throughput is often just as important as accuracy. To capture that real-world constraint, we measure inference efficiency by running the entire OlmOCR-Bench evaluation end-to-end (1,403 pages) and report pages per second: the total number of pages divided by the wall-clock time needed to complete the benchmark.
What we’re releasing
LightOnOCR-2 is released as a small model family so you can pick the right tradeoff for your workflow instead of forcing everything into one checkpoint.
Default model: best OCR
LightOnOCR-2-1B is the OCR-only checkpoint and our default recommendation for most usages. If your job is “turn PDFs into clean text/Markdown reliably,” this is the one to use as it’s the strongest choice for transcription quality.
OCR + lightweight layout cues: bbox-capable variants
We’re also releasing bbox-capable checkpoints that can output bounding boxes for embedded figures/images (in addition to OCR). This is useful when you want lightweight localization (e.g., “extract text, and also tell me where the figures are”), without moving to a full document layout pipeline.Because OCR and bbox objectives can pull the model in slightly different directions, we provide two options instead of overloading the default checkpoint:Rather than overloading the default model, we provide:
LightOnOCR-2-1B-bbox: a bbox-focused checkpoint (best localization),LightOnOCR-2-1B-bbox-soup: a merged tradeoff checkpoint (balanced OCR + bbox).
Base checkpoints (for fine-tuning / research)
Finally, we’re releasing two base checkpoints (one with bboxes, one without). These are meant for people who want to:
- fine-tune on their own data/domains,
- reproduce or extend our post-training steps (including RL recipes described in the preprint),
- experiment with merges to build even stronger variants.We provide here a recipe for finetuning using the models.
Transformers support: easier to run and fine-tune
LightOnOCR is now usable directly through the Hugging Face Transformers ecosystem (support has been merged upstream). Practically, that means:
- you can run it with standard Transformers tooling (no requirement to start with vLLM),
- fine-tuning is straightforward with common HF workflows (LoRA / PEFT / Trainer),
- and CPU/local usage is feasible for lower-throughput settings (hardware-dependent, but much more accessible than “GPU-only pipelines”).


.avif)
.avif)